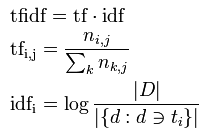平素は大変お世話になっております。 ミエルカAIブログ 編集チーム一同です 本記事(https://mieruca-ai.com/ai/fisherian-bayesian/ ※現在は内容非公開)の内容に 誤りや誤解を招く表現が、ございました。 つきましては、指摘いただいたご記載含め、 まずは、記事内容の取り下げを早々に行いました。(2019年7月16日10時35分) 今後、内容につきましては、鋭意検討していく所存です。 お手数をおかけしまして、恐縮の至りではございますが 何卒よろしくお願いいたします。 この度は、多大なるご迷惑をおかけしましたことを 心よりお詫び申し上げます。 今後このようなことのないように徹底してまいります。 どうぞよろしくお願いいたします。 ミエルカAIブログ 編集チーム一同
【技術解説】マルコフモデルと隠れマルコフモデル
執筆:金子冴
今回はマルコフモデルと,マルコフモデルを拡張した隠れマルコフモデルを題材に,それぞれのモデルの解説と2つのモデルの違いについて解説する.
まずはマルコフモデルについて解説しよう.
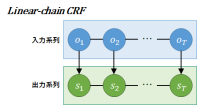
【技術解説】CRF(Conditional Random Fields)
執筆:金子冴
今回は,形態素解析器の1つであるMeCab内で学習モデルとして用いられているCRF(Conditional random field)について解説する.
初めに,CRFのwikipediaの定義を確認しよう.
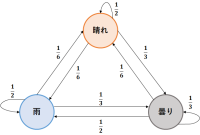
【技術解説】bi-gramマルコフモデル

執筆:金子冴
今回は,形態素解析器の1つであるMeCab内で解析モデルとして用いられているbi-gram マルコフモデルについて解説する.
初めに,bi-gramの元となっている,N-gramという手法を解説しよう.
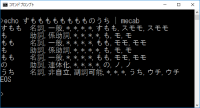
【技術解説】形態素解析とは?MeCabインストール手順からPythonでの実行例まで
執筆:金子冴
今回は,自然言語処理分野で事前処理として用いられることが多い形態素解析に着目し,形態素解析を行う目的や,主要な形態素解析器の比較を行う.また,形態素解析器の1つであるMeCabを取り上げ,インストール方法や実行例,商用利用の注意点等を確認する.また,次回以降の記事にて,MeCabで用いられている以下のアルゴリズムについて解説する.
●bi-gram マルコフモデル(解析モデル)
●CRF(Conditional Random Fields)(学習モデル)
●Viterbi(解探索アルゴリズム)
初めに,形態素解析の概要とメリット,注意点について確認しよう.
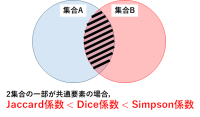
【技術解説】集合の類似度(Jaccard係数,Dice係数,Simpson係数)
執筆:金子冴
前回の記事(【技術解説】似ている文字列がわかる!レーベンシュタイン距離とジャロ・ウィンクラー距離の計算方法とは)では,文字列同士の類似度(距離)が計算できる手法を紹介した.また,その記事の中で,自然言語処理分野では主に文書,文字列,集合等について類似度を計算する場面が多いことについても触れた.今回は集合同士の類似度を表現する以下の3つの係数と計算方法について解説する.
●Jaccard係数
●Dice係数
●Simpson係数
その前に,自然言語処理で類似度を表す指標について確認しよう.
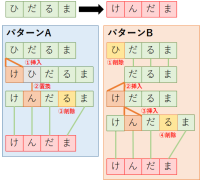
【技術解説】似ている文字列がわかる!レーベンシュタイン距離とジャロ・ウィンクラー距離の計算方法とは
執筆:金子冴
人はだれしも間違いを犯すものである.徹夜で仕上げた報告書を提出した後,よく見直してみると誤字脱字が山ほど見つかった経験が読者にもあるだろう(もしかすると私だけかもしれないが).そういう時,もし自動で間違っている単語を見つけてくれるプログラムがあったら…と考える人もいるかもしれない.そこで今回は,文字列同士の似ている度合いを計算する2つの手法を紹介しよう.
●レーベンシュタイン距離(Levenshtein Distance)
●ジャロ・ウィンクラー距離(Jaro-winkler Distance)
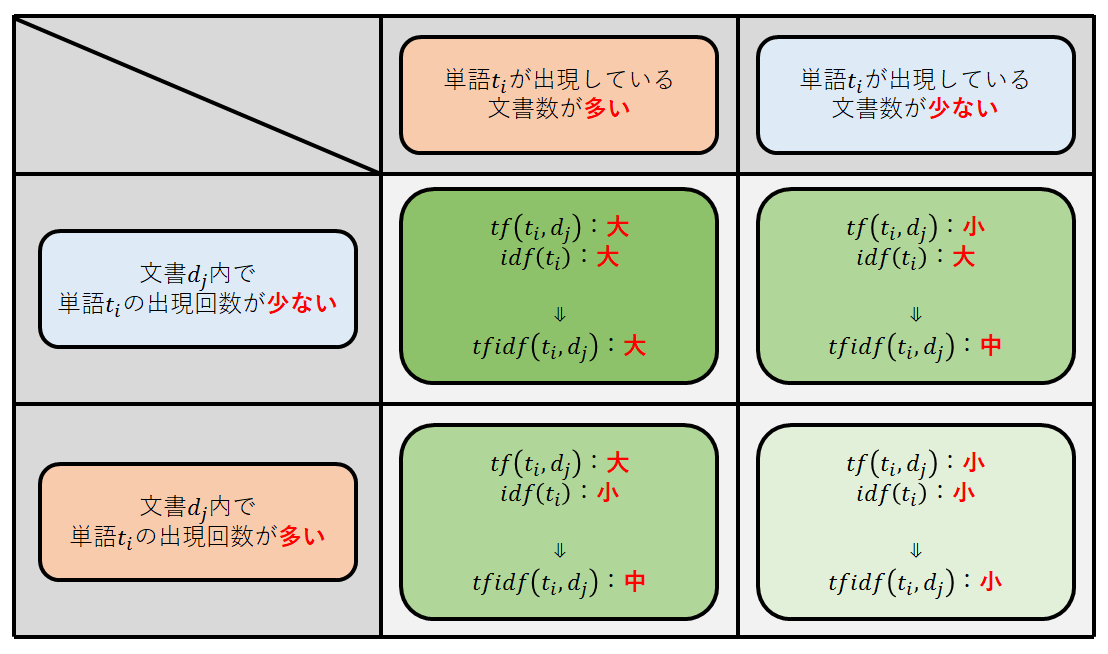
【技術解説】単語の重要度を測る?TF-IDFとOkapi BM25の計算方法とは
執筆:金子冴
世の中には単なるメモ書きから予算案,スポーツ記事や文学作品等,数えられないほどの文書が存在する.例えば,その数多の文書から「スポーツに関する記事が読みたい」と思った時,どれがスポーツに関する文書なのか判断する必要があるだろう.しかし,すべての文書を目で読んで判断することは到底不可能であり,現実的ではない.今回は,数多の文書に含まれる単語の重要度を測る手法であるTF-IDFとOkapi BM25について解説する.
研究ブログ
【研究】日経新聞さんの記事作成AIを6時間で作れるかチャレンジしてみた(完全自動「決算サマリー」をみて)

言語処理な皆さん、こんにちは。CROの副島です。
1月25日、日経新聞さんに掲載されていた「AIで自動的に決算から記事を作成する」というのが、自然言語処理の勉強になるということで、6時間(約半日)でどこまで行けるか、実行してみました。
また、個人的に「経営の意思決定」に必要な情報として「営業利益、経常利益、売上高の昨対実数」を収集したかったのでそれもかねて。
(more…)
研究ブログ