
ストップワードの除去は自然言語処理やテキストマイニングにおける重要な作業です.
解析の精度を上げるために不要な記号や単語を等をデータセットから除去します.
ストップワードの選定にはタスクに特化した分析が必要ですが,ある程度整理されているデータがあるととても助かります.
そこで,今回は私が自然言語処理のタスクでよく行う,日本語のストップワードについてまとめました.
また単語の分布などから,品詞ごとのストップワードに対する考察も行いました.
このことからストップワードを介して自然言語処理のあまり語らることのない知識などをご共有できればと思います.
(この記事の考察部分は主に自然言語処理の初心者を対象とした入門記事です.)
目次
1. 自然言語処理・ストップワードとは
2. 分析の対象
3. 単語の分布に対する考察
┣ 出現頻度 上位300件
┗ 出現頻度と単語
4. 品詞ごとに考察
┣ 名詞
┣ 動詞
┣ 副詞
┣ 助詞
┣ 接続詞
┣ 記号
┣ 助動詞
┣ 感動詞
┣ 感動詞
┗ 連体詞
5. 便利な正規表現
┣ ひらがな
┣ カタカナ
┣ 漢字
┗ 常用漢字一覧
6. おわりに
自然言語処理・ストップワードとは
自然言語処理
小学館の『日本国語大辞典 第二版』には見出し語として50万語ほど記載されているそうです.
コンピューターで言語を処理する際には,それを符号化する必要があります.
我々が普段使用する英語や日本語などの言語は自然言語と呼ばれ,それをコンピューターで処理することを自然言語処理といいます.
単語の数値化
自然言語処理では形態素解析やn-gramという手法を用いて文章を単語もしくはある単位に分割します.
その分割された単位に通し番号(インデックス)を付け単語を数値に置き換えます.
そのため,単語は「単語とインデックスの関係を記述した辞書」を介して数値化されます.
この数値を元に分析などの処理を行います.
ニューラルネットワークに単語を入れる際には単語自体をベクトル化(エンベディング:Embedding)する必要があります.
この方法にはone-hotベクトルの利用やword2vecを用いたベクトル化などがあります.
one-hotベクトル
もっとも単純な単語のベクトル化手法であります.
まず,単語の辞書の要素数分の長さを持つ0で埋め尽くされたベクトルを用意します.
次に,エンベディングするある1単語のインデックスに相当する箇所を1に置き換えます.
以上です.
例として次のような辞書があるとしましょう.
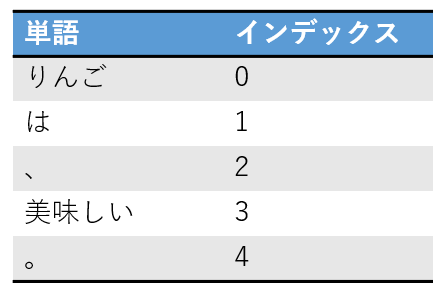
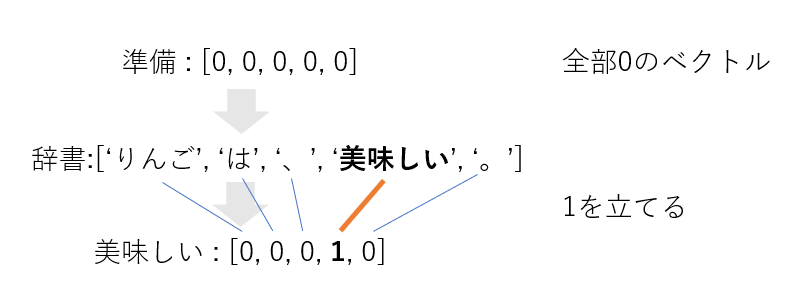
これから「美味しい」のベクトルを得ると以下のようなベクトルが得られます.
文章のベクトル化
文章を処理する際には数値化された単語から文章のベクトルを生成し,機械学習のモデルに入力し学習させます.
文章のベクトル化に用いられる方法にはBOW(Bag-of-Words)などがあります.
BOW(Bag-of-Words)
BOWとは文章などの単語の集合をベクトル化する手法です.
one-hotベクトルの時と同様に0で埋め尽くされたベクトルを用意し,集合に含まれる単語に対応する個所にのみ1を立てます.
先ほどone-hotベクトルの項で使った例をもとに,「美味しい、りんご美味しい」をBOW表現すると以下のようになります.
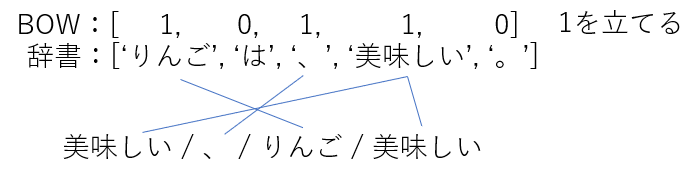
もっとも単純なone-hotベクトルは単語の出現頻度(TF:Term Frequency)を考慮しないため上記のようになるが,頻度を考慮して以下のようにあらわすこともあります.
[1, 0, 1, 2, 0]
また,各要素にTF-IDFという指標を用いることもあります.
問題点
このように,単語をベクトル化するわけだが,先ほども上げたように日本語の単語数は膨大であります.
これをもしそのままベクトル化して利用すると何十万次元のベクトルの演算が必要となり,メモリ不足を引き起こしたり,コンピューターの寿命が尽きるまでに計算が終わらなくなったりもします.
解決策
これらを解決するためには,用いる単語の数を削減することが不可欠であります.
情報量が少ない単語,出現頻度が少ない単語,タスクに関係が無い単語を省く必要があります.
これらの,いらない単語をまとめたものをストップワードといいます.
分析の対象
今回は2018年5月31日時点でのwikipediaのダンプを元に分析を行います.
日本語における頻出単語はほとんど不変なため,時がたってもその影響は大きくないと思います.
単語の分布に対する考察
はじめに
単語の出現頻度をもとに分析を行っていきます.
出現頻度 上位300件
(半角スペース区切り,半角スペースは排除してあります.)
。 は 、 の ( ) に で を た し が と て ある れ さ する いる から も ・ として 「 」 い こと – な なっ や れる など ため この まで また あっ ない あり なる その られ 後 『 』 へ 日本 という よう ( 現在 もの より だ おり 的 中 により ) 2 による 第 なり によって 1 これ その後 ず , か 時 なく られる だっ において 者 なかっ 行わ 多く しかし 3 せ 他 名 出身 それ について 間 当時 上 ば 存在 受け . 呼ば 同 なお できる 目 行っ 内 う 数 のみ 前 以下 き : 元 化 4 等 および 使用 でき 同年 主 場合 際 一 約 における さらに 一部 所属 人 以降 ら 活動 5 中心 作品 いう 知ら 同じ 初 だけ 多い 時代 以上 生まれ 発表 2010年 にて 見 務め 持つ とともに 大 参加 頃 位置 2007年 2009年 2008年 開始 うち 行う ほか 特に 全 ながら 当初 発売 せる 2011年 家 かつて 下 卒業 一つ 2006年 6 でも 年 2012年 形 用い に対して 最初 / 本 考え なら 以外 関係 一方 それぞれ 各 同様 4月 経 2013年 と共に 2005年 そして 3月 地域 必要 これら 及び 一般 用 2014年 結果 可能 現 開催 事 ものの 利用 にかけて 部 影響 設立 記録 得 アメリカ 通り とも 彼 2015年 自身 登場 始め または 担当 変更 意 味 たり 側 とき 開発 設置 代表 ほど ので 構成 ただし 二 2004年 郡 初めて たち 部分 2016年 最も 放送 7 旧 地 最後 アメリカ合衆国 10月 世界 研究 大学 8 系 大きな 活躍 獲得 続け 以前 全て 問題 性 与え 9月 父 含む といった ほとんど 7月 ところ 2017年 2003年 向け 持っ 2000年 加え 使わ 型 6月 に関する 出場 12月 目的 高い 名称 に対する 1月 万 実際 5月 -1 名前 様々 再び 10
前半にはひらがな一文字から成る助詞が多く出てきています.
また,句読点や各種カッコなどの記号も見られます.
ところどころに,「日本」,「現在」,「第」,「同」などのwikipedia特有の表現に依存ていると考えられるものも含まれています.
このことから,ストップワードを選定する際にはもとにしたデータセット固有の表現を必要に応じて除去する必要があることがわかります.
具体的に5000単語ごとにどのような単語がランクインしているかを確かめてみます.
これにより,DeepLearningなどのvocab,BOWとしてどこまで用いるかの目安を求めます.
(半角スペース区切り,半角スペースは排除してあります.)
rank word
1 。
5000 3月18日
10000 103
15000 挙行
20000 先着
25000 文集
30000 Ben
35000 ビーイング
40000 笑わ
45000 ちご
50000 リコー
55000 印刷技術
60000 詰まる
65000 アンシュルス
70000 付き従い
75000 マラケシュ
80000 ディオニュシオス
85000 正月三が日
90000 ぴん
95000 俊之
100000 銭形平次
数字は排除して考えるべきですが複雑な排除過程を用いると再現性が低くなるため,あえてそのまま残しておきました.
25000番目までは普通の文章でもよく出てきそうな単語が並んでいます.
75000番目以降は人名や固有名詞が多くなってくるようです.
私がone-hotベクトルとしてニューラルネットワーク系のモデルで単語を学習させる際には,大体40000くらいで足切りしています.
その前に数字を省いたり,単語を原型に戻したりする処理をはさむこともあります.
出現頻度と単語
自然言語における単語の出現頻度には偏りがあります.
実際にwikipediaにおける出現頻度上位30個の単語とその出現回数,累積和,累積和の全体に対する累積比率を見てみましょう.
rank word frequency sum percent
1 。 1042175 1042175 0.602441
2 は 1040934 2083109 1.204165
3 、 1030243 3113352 1.799709
4 の 1007411 4120763 2.382054
5 ( 985441 5106204 2.951700
6 ) 969404 6075608 3.512075
7 に 931459 7007067 4.050516
8 で 890582 7897649 4.565327
9 を 844499 8742148 5.053499
10 た 837914 9580062 5.537865
11 し 789369 10369431 5.994169
12 が 782454 11151885 6.446475
13 と 779079 11930964 6.896831
14 て 775210 12706174 7.344950
15 ある 716627 13422801 7.759204
16 れ 687856 14110657 8.156828
17 さ 682101 14792758 8.551124
18 する 613570 15406328 8.905805
19 いる 611892 16018220 9.259516
20 から 597215 16615435 9.604743
21 も 564386 17179821 9.930993
22 ・ 557556 17737377 10.253295
23 として 505984 18243361 10.545785
24 「 481767 18725128 10.824276
25 」 477105 19202233 11.100072
26 い 441220 19643453 11.355124
27 こと 430190 20073643 11.603800
28 – 415687 20489330 11.844093
29 な 411968 20901298 12.082236
30 なっ 409480 21310778 12.318940
日本語において可能な単語を網羅的に含んでいるwikipediaにおいてさえ,出現頻度の高い上位22個の単語だけで全体の約10%も占めていることがわかりました.
以下に日本語wikipediaにおける単語の出現頻度のパレート図を示します.
(小さければ「ctrl」+「+」などで拡大してください.)
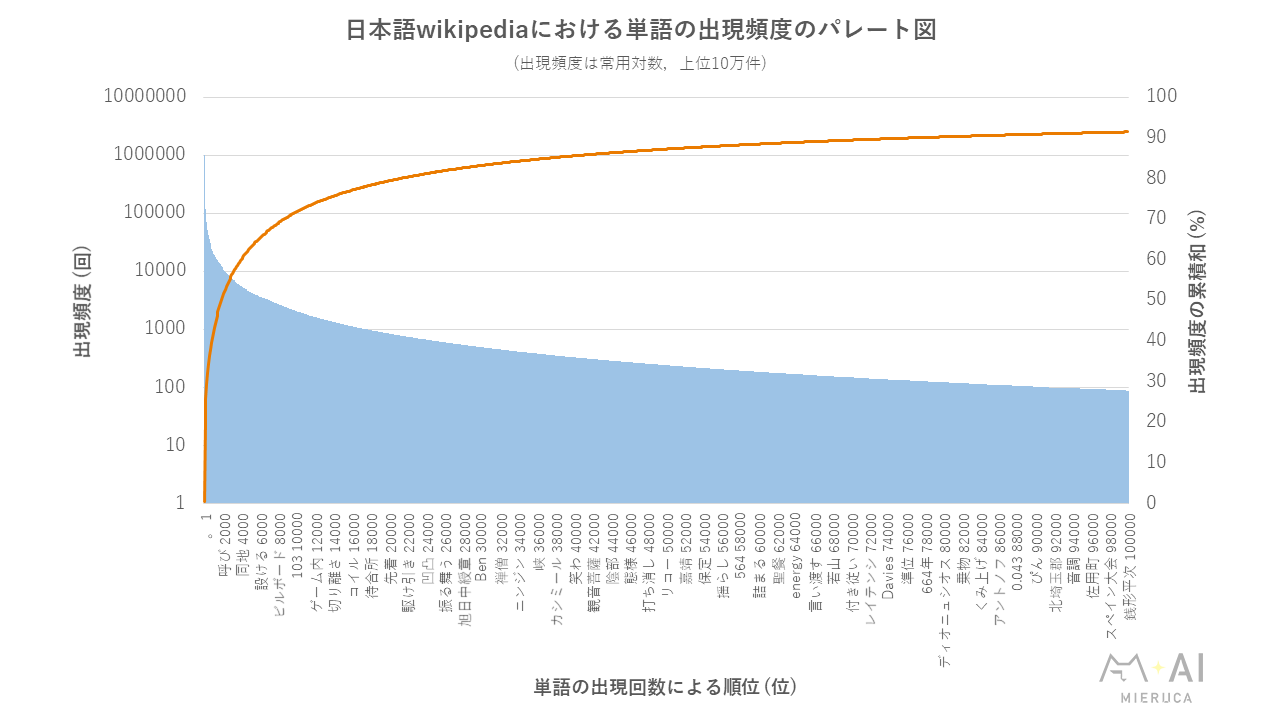
この図は,出現頻度上位10万語の出現回数のパレート図です.
おおよそ,100単語で20%,400単語で30%,900単語で40%,1900単語で50%,4,000単語で60%,8,600単語で70%,21,100単語で80%,77,550単語で90%を占めています.
1万単語くらいから累積頻度の伸び率が鈍化していくのでそこで切ってしまってもいいかもしれないですね.
ちなみに今回の分析に使ったwikipedia全体では,3,034,434単語(mecab-ipadic-NEologd + janomeで分割),1,279,801文(‘\n’区切り)ありました.
品詞ごとに考察
はじめに
品詞ごとに分析を行っていきます.品詞はjanomeやMecabなどのライブラリを使った形態素解析により求めます.今回はインストールが簡単なjanomeで行いました.単語を形態素解析器にかけると以下のような出力が得られます.
ポータルサイト 名詞,固有名詞,組織,*,*,*,ポータルサイト,*,*
すごい 形容詞,自立,*,*,形容詞・アウオ段,基本形,すごい,スゴイ,スゴイ
1612 名詞,数,*,*,*,*,1612,*,*
せいぜい 副詞,助詞類接続,*,*,*,*,せいぜい,セイゼイ,セイゼイ
ワーナー・ブラザース 名詞,固有名詞,組織,*,*,*,ワーナー・ブラザース,*,*
この結果には原型,品詞,活用,読み方などが示されています.
自然言語処理では,これをもとに分析やストップワードの選定を行います.
名詞
名詞のうち,出現頻度上位300語を確認します.
(半角スペース区切り,半角スペースは排除してあります.)
こと – ため 後 日本 ( 現在 もの おり 的 中 ) 2 1 これ その後 , 時 者 多く 3 他 名 出身 それ 間 当時 上 ば 存在 . 目 内 数 前 以下 元 化 4 等 使用 同年 主 場合 際 一 一部 所属 人 以降 ら 活動 5 中心 作品 初 時代 以上 生まれ 発表 2010年 務め 大 参加 頃 位置 2007年 2009年 2008年 開始 うち ほか 全 当初 発売 2011年 家 下 卒業 一つ 2006年 6 年 2012年 形 最初 / 本 考え 以外 関係 それぞれ 同様 4月 経 2013年 2005年 3月 地域 必要 これら 一般 用 2014年 結果 可能 現 開催 事 利用 部 影響 設立 記録 得 アメリカ 通り とも 彼 2015年 自身 登場 始め 担当 変更 意味 側 とき 開発 設置 代表 構成 二 2004年 郡 部分 2016年 放送 7 地 最後 アメリカ合衆国 10月 世界 研究 大学 8 系 活躍 獲得 以前 全て 問題 性 9月 父 7月 ところ 2017年 2003年 向け 2000年 型 6月 出場 12月 目的 名称 1月 5月 -1 名前 様々 10 号 8月 出演 別 デビュー 点 状態 発生 11月 新 2002年 就任 時期 次 受賞 死去 0 面 式 特徴 2001年 その他 監督 日 ここ 多数 映画 終了 東京 由来 選手 理由 イギリス 出 新た 末 決定 三 線 社 自分 手 いずれ 女性 計画 内容 戦 採用 チーム 方 以来 場所 例 国 2月 初期 実施 版 シリーズ 建設 力 のち 最大 すべて フランス 人口 優勝 重要 通常 行い 制作 販売 成功 of 1999年 時点 村 作 自ら 人物 以後 収録 期 公開 時間 はじめ 非常 大会 予定 まま 国内 対応 全体 表記 展開 地区 南 2年 運営 中国 町 たい メンバー 番組 度 発見 評価 ドイツ 子 1998年 参照 物 翌年 会 北 何 所 軍 有名 機 教授 程度 歴史 近く 1997年 事業
上位の方は,ほとんどの文章において自立的に用いられる語というよりは何かを補助する役割で用いられる単語が出現しているようです.wikipediaの場合には2000年代の年数が多く出現していることがわかります.数字に重きを置かないタスクにおいてはこれらの数字を0に統一するという前処理が多々見られます.これは,細かい数字の値に着目するのではなく,そこに数字が入ることのみを学習すればよいという場合に使われます.タスク依存ではありますが,このような情報の丸め込みは常套手段です.
下位の方になると国名などのコーパスに特有な名詞がみられます.このような名詞は一般的に取り除かない方が良いです.
品詞を「名詞-一般」に絞ってみます.
もの 中 時 者 他 名 出身 間 上 ば 目 内 数 元 主 人 ら 中心 作品 初 時代 生まれ 務め 大 家 下 一つ 年 形 最初 本 考え 経 地域 一般 用 現 事 部 得 通り とも 自身 側 郡 部分 地 最後 世界 大学 系 性 父 ところ 向け 型 目的 名称 名前 様々 別 点 状態 新 次 面 式 特徴 日 映画 選手 理由 線 社 自分 手 女性 内容 戦 チーム 場所 例 国 初期 版 シリーズ 力 最大 人口 通常 行い 時点 村 作 人物 期 大会 国内 地区 南
すると,先ほどの単語群のうちの情報量の少なそうな単語が省けました.
これらの単語は多くの場合で分析に必要不可欠な単語です.
この結果から,「名詞」と「名詞-一般」の差分をストップワードに入れると良さそうといった工夫も見えてきますね.
ストップワードの選定などの作業は,人手ですべてを定義するのは難しいのでなんらかのヒントをもとに生成した集合を組み合わせて定義していくと楽に進みます.
動詞
動詞のうち,出現頻度上位300語を確認します.
(半角スペース区切り,半角スペースは排除してあります.)
し ある れ する いる い なっ れる あり なる られ なり られる 行わ せ 受け 呼ば できる 行っ でき いう 知ら 見 持つ 行う せる 用い たち 続け 与え 含む 持っ 加え 使わ 異なる いく よる 入っ 果たし 入り いっ 言わ 挙げ 認め 伴い しまう 含ま 続い しまっ 入る み 含め 受ける 合わせ 使っ 至る よれ 示す 作ら 迎え 選ば 残し 出し 離れ 務める 言う 述べ いわ 求め 残っ 持ち 続く 示し 入れ 置か 呼ぶ 進め 思わ くる かけ 指す しよ 似 終わっ 始まっ 結ぶ 置く 来 得る もっ 見る 書か 始める 属する 敗れ 異なり 見せ 描い 比べ 有する 描か 起こし 語っ あたる 生まれる 用いる 目指し 作っ 分け 使う 除く 応じ 戻っ 訪れ すれ 収め 受けて 進ん 向かっ 果たす書い 言っ 始まる 属し 至っ 持た 起き 行く 出来る 出る 向かう せん 結ん 与える 生じ かかわら 伴う 作る 変え とっ 呼ん 取っ 置い 建て 限ら 称し 沿い 残さ 残る 率いる 優れ 基づい 有し 続ける 通っ 終わり 学ん 達し 起こっ 超える 失っ 演じ 開か 過ぎ しまい 命じ 基づく 送っ 続き 求める 記さ 見える 表す 渡っ 出さ 出す 知っ した 繰り返し 考える 終え 進む 行き 流れる 称さ 率い 変わっ 異なっ 目指す 除い あげ 思っ 扱う 継い 視 生まれる 渡り 進み 住ん 住む 占め 学ぶ 知る いえる 戻り 決まっ 描く 沿っ 過ごし 許さ 問わ しょう 伴っ 開い かかる 取る 言える 戻る しない 守る 代わっ 立っ 手がけ 記し 付い 占める 現れる 言え とる 基づき 加わっ 取り あろ 呼び 及ぶ 移っ 起こる 働い 違う 通る 聞い 失わ 次ぐ 終わる 転じ 扱わ 除き 挙げる せよ 図る 当たる 掲げ 並ん 生じる 読み くれ 示さ 越え 行なっ 組ん 移し 乗っ 亡くなっ 関わっ ちなん 死ん 戦っ 送ら 行なわ 走る きた 広がっ させ 接し 来る かかっ 接する 入れる 仕え 関わる やっ 関わら 迎える しよう 戦う 図っ 選ん 防ぐ 生き 取ら 伝える 起こり つける 表し 言い 担っ 破り 通う 述べる 築い
上位の単語はなにかに接尾する単語なので,これらはストップワードにしてもよいかもしれないです.それ以外の単語に関しては文字通り動作を表すものがほとんどなので情報量が多い品詞です.「呼ば」や「知ら」が頻出なのはwikipediaの特徴です.一般的な動作の分布が欲しい場合は,QAサイトやSNSやブログをクロールし分析するといいでしょう.
形容詞
形容詞のうち,出現頻度上位300語を確認します.
(半角スペース区切り,半角スペースは排除してあります.)
ない なく なかっ 多い 高い 大きく 長 強い 新しい 近い なけれ 広く 高く 無い 少ない 強く いい 長い なし 少なく 多かっ 大きい やすい 良い 低い 古い 長く 高さ 数多く 低 大き 無く 長さ よい 短い 深い 激しい 若い 小さい 良く 早く 広い 深く く 無かっ 強 難しい 厳しい 低く 余儀なく やすく 多 小さく 重 激しく 幅広い 珍しい 悪い にくい 美しい くらい 幼い 白い 古 早い 広 悪く 短く 狭い 新しく 正しい 詳しく うまく 赤い 幅広く 珍しく 黒い 厳しく 著しく ほしい 弱い 著し 近 無し こく 数少ない 難しく 親しま 薄い 高かっ 著 高い 評価 欲しい 少なかっ 重い 明るい 異 速 やす 遅く 悪 詳しい 厚 細かい 軽 安 大きかっ 長い間 愛し 薄く なき 遅い 狭く 軽い 強かっ 等しい にくく 細長い 細い 速い 少 著しい 素晴らしい 暗い 弱く 軽く 浅い 明るく 遠 重く 遠い 望ましい 貧しい 乏しい 濃い 細かく 若 速く 深さ 厚く 青い 良かっ 厚い まる 親しく 良さ 上手く 美し 深 鋭い ひろし かた 早 楽しん 低かっ ふさわしい 名高い いち早く 面白い こい 安い 細く 少なからず 美しく 若さ 長き 暗 がたい 素早く 太い 安く 重さ 淡 甘い ひどく 悪かっ 優しい 若く 親しい くさい 若き 楽しい 白く 悪さ 貴 よかっ 乏しく 興味深い 苦しい 等しく おも 太く 細長く 速さ 黄色い 丸い たかし 柔らかい 黒く 快 すい 赤く づらい 硬い 温 狭 ひどい 重き 早くも くろ 根強い 鋭く 芳しく 恐ろしい 冷たい 痛 色濃く 暗く 固 寒さ 熱い浅く 明る 細 難い 甘 濃 難しかっ 数多い 深かっ 丸く 力強い 楽しく 相応しい 柔らかく うし 濃く 辛い 固く 近かっ 寒い 易い 臭い 優しく くち 良き 若くして 遅 少な 淡い 幼く はやし 快く 暖かい 硬 ほし 険しい 難し おかしい 疑わしい うき 楽しま 固い 硬く 好ましく こふん 根強く 好ましい 面白く 甘く 高い 位置 遅かっ 酷い 見よ こし 激し 長かっ 怖 危うく 輝かしい 暑い 悲しい 若い おかしく っぽい 若き日 おおい くいん 小さかっ怖い 小さ 惜しま 浅 力強く 楽しさ 正し うまい 緩い すごい きよし
「ない」系の単語を除けばほとんどが自立語で,これもまた情報量が多い品詞です.ある事象の度合いや様相を表す単語が多いため,直感的にも大切そうだとわかります.
副詞
副詞のうち,出現頻度上位300語を確認します.
(半角スペース区切り,半角スペースは排除してあります.)
より さらに 特に かつて 初めて 最も ほとんど 万 実際 再び 同時に ほぼ よく そのまま どう こう そう すぐ あまり 相当 しばしば 既に わずか 比較的 更に まだ 全く もう かなり 元々 つい まず やがて 古く やや すでに 共に 常に 次第に 引き続き 少し もともと 単に 極めて しばらく およそ 再度 次々 徐々に ともに 少なくとも 一旦 ついに 必ず ごく 別に やはり ようやく 突然 とう 必ずしも むしろ もし ある程度 はっきり 互いに 長らく 間もなく 改めて 当然 まったく まもなく なぜ 当て おそらく 度々 決して 僅か もちろん たびたび とても 主として もっと とりわけ あくまで 概ね 大いに そうした 順次 あまりに いか なかなか 中でも とくに 一気に それほど いつも ずっと ちょうど 急遽 多少 突如 本当に おおむね 直ちに もはや 時に でん いったん 将 正しく あらかじめ はじめて 時には たとえ これから 未だ 極 依然として きわめて あえて 実に 一躍 しっかり 遂に あくまでも まさに 順に 早々 いろいろ もっぱら 充分 かく ゆっくり 便宜上 一層 いかに まるで 何とか おおよそ 終始 仮に 時々 いきなり 遥か おもに 早くから ますます たまたま たった 一応 いわば 色々 別途 とく いっぱい 未だに ピン 果たして なんとか もう一度 ばん 多々 専ら いまだ 相まって なるべく かえって ちょっと りん もとより 二度と ただちに やっと すぐさま それなり どうしても やむなく さほど なかでも 恐らく 公然 予め たちまち あたかも ふたたび そっくり 程なく 続々 たいてい 暫く ことごとく きちんと バン 直ぐ 極力 目の当たり 絶えず すっかり 総じて 幸い なおも 早速 何ら できるだけ バラバラ 世に 概して 少々 どんどん 一般に わざと そのままで 敢えて 再三 今や いざ とにかく 真に さと 依然 相変わらず 終生 仲良く 何故 わざわざ 且つ ひたすら いまだに 堂々 まっすぐ 辛うじて どうして いよいよ ひいては かろうじて いつしか ともかく 転封 おそらくは 勿論 然 あっさり かねてから ふつう 惜しくも 後で 一味 ニコニコ動画 ゆめ はた もしも ちゃんと 時として もう少し さすが バーン まだまだ 思わず 異に 宜 遅くとも 奇しくも 尽くさ こうつう いっそう どうどう 多分 それだけ 到底 だんだん とりあえず とうとう どうし 無理やり ニコニコ生放送 たたえ しばし さながら 断固 細々 何故か だいたい ふんだんに ゆったり ふと どんなに そこそこ 道道 ことに しだいに 唯 きっと こうか 一向に 全然 丁度 余計 現に そうだ
見てわかるように情報量は少ない品詞です.これらの単語がなくても文章は成立するため,私はこれらをストップワードにすることが多いです.しかし,後半を見てわかるように形態素解析も完全ではないので注意が必要です.
助詞
助詞のうち,出現頻度上位100語を確認します.
(半角スペース区切り,半角スペースは排除してあります.)
は の に を て さ から も として な や など まで へ という により による によって か において について のみ における だけ にて とともに ながら に対して と共に ものの にかけて たり ほど ので といった に関する に 対する に対し ん しか にとって つつ に関して わ なさ を通じて よ ずつ ばかり にわたって にあたる ね にも こそ を通して かい に際して のに をもって さえ にわたり すら に従って にあたって って にわたる にあたり に従い べ ぜ ぞ ど け か所 にし につき ねん に当たる に際し につれて とか だり につれ をめぐって てん もん に当たって にまつわる の子 にあ は元 を以て デ ぐらい にかけ やら かな しも なんて に関し
これもストップワードの代表的な例です.BERTのような構文の依存関係まで学習できるようなモデルでない限り,これもあまり役に立ちません.特にBOWのように単語の集合を分析する場合には省くことがほとんどだと思います.しかし,構文解析や照応解析ではこれが一番重要といっても過言ではないでしょう.
接続詞
接続詞のうち,出現頻度上位100語を確認します.
(半角スペース区切り,半角スペースは排除してあります.)
で が また しかし なお および でも なら 一方 そして 及び または ただし あるいは 同じく 例えば かつ では そこで もしくは ただ すなわち だが つまり もっとも ちなみに しかしながら それでも ところが たとえば こうして 次いで ないし したがって 次に 又は しかも 但し 実は じゃ 尚 従って そもそも よって 反面 並びに 否 けど ついで 故に 又 それから またがる 追って すると 一方的 或いは ならびに ゆえに 即ち なおかつ だから それに 即 若しくは がよく どころか まずは ならでは またがっ それで だって なぜなら かくして 因みに けれども それとも 本当は というのも がそ またも そうして けれど いっぽう がさ 一方通行 それでは またい そのうえ がつ ところで でのみ いえよ それどころか 一方向 さて なおき ないしは 即戦力 またがり
これもまた,単語ベースの分析ではあまり情報量のない単語です.しかし,文と文の関係を記述する語なためタスクごとに扱いを変えるべきでしょう.
ところで,接続詞ってこんなにあるんですね.逆接の頻度が高いのは面白い発見で,何か言えることがありそうです.この量の接続詞を使いこなせるようになれば流ちょうな文章が書けそうですね.
記号
記号のうち,出現頻度上位200語を確認します.
(半角スペース区切り,半角スペースは排除してあります.)
。 、 ( ) ・ 「 」 『 』 : 〜 = ※ ” “ → … × ! / ? ○ ノ 〈 〉 々 , & ☆ ― + α 〒 《 》 ‐ …。 【 】 ★ ; ’ β (- − 〔 μ 〕 ˈ > () < ́ ―― . ə m [ ] γ 〇 ■ ● ː (= * (株) △ ε ▲ π φ δ ‘ −1 σ Δ θ λ ◎ ω 。( Σ ─ ν ɛ ɪ (+ Ω ノルマン人 ρ □ ← ゝ 。}} τ A (笑) ×3 κ ɔ η @ (~ ′ ʃ ノルマン Ἀ (. ο 「( ÷ 「~ ʊ ◆ (? (≒ (( ζ (財) ↑ ι Γ χ محمد 〇〇 。! Λ ˌ ʿ 。- B 「- (- } Ζ ◇ بن £ ψ (( Φ { (’ υ ʒ Α (社) 。}}}} ノリス ɾ عبد T 。) ɡ əˈ ゞ t ノウサギ −2 ɣ Π ɒ ↓ ʻ ︎ | C Ε 『’ F ξ ɑ M ノモス 〆 D (” Ζガンダム ʌ H V ¥ X J ɐ ʁ ɔː (有) −3 E (— ɨ (「 S ʲ ○× الله cm ノリッチ
たいていのタスクではノイズとなる品詞です.情報量がないうえに,場合によっては文字化けしたりする厄介な文字が多いです.各種カッコやギリシャ文字などは,正規表現を使って文字コード上の範囲を指定し排除することが多いです.もしくは日本語や英語などの対象となる言語全体を正規表現で規定しておき,そこらかはみ出るものに関しては排除するといった工夫をするのも常套手段です.
余談として,😄絵文字😄は情報量が非常に多い記号です😆.感情の現れだったり,それ自体が文の要約であるといった見方もできるので,ストップワード⛔に用いるかどうかはタスクごとに考える必要があるといえるでしょう🤔.
助動詞
助動詞のうち,出現頻度上位100語を確認します.
(半角スペース区切り,半角スペースは排除してあります.)
た だ ず だっ き べき じ たら である ます だろ べく ぬ です つ まし らしい り たる る じょう ませ らしく たかっ まい でしょ たろ でし べし じけん じょ たなか ましょ らし た者 なが なのか ごとく 如く りし つじ らしき ござい た事 だら たかお た分 やし つち つぼ じた だん りの たもう たじ ださ やな 如き じどうしゃ じょうやく りお やせ ひん りぼん じょうほ りな じゆう ごとき たな やの べから っし じち だいち た紙 たくや た方 りひ やた た面 つちや たは まじ じだ じどうし なのは だむ た力 るし た値 なば らしくない じどう た量 たひ るか たかつ じょうこう た人 た産
これらも情報量が少ない単語です.だいたいの単語がひらがな1文字か2文字なのでそれらを正規表現でまとめて省くこともあります.
感動詞
感動詞のうち,出現頻度上位143語を確認します.
(ノイズ,半角スペース区切り,半角スペースは排除してあります.)
あっ よう う お あれ ま ほう いえ うえ おお よし おい ぎょ ノー あら はい うん なんと オー いや ありがとう フェロー おは ああ サヨナラ うごう さよなら はっ うお ねえ そら エイ おや ねぇ あらわ まあ うんどう おはよう サヨナラ フェ ええ さらば ふん アッ おっ ようこそ じゃあ イヤ うしん おおわ さあ さようなら うご こんにちは あらか うげん うな ういち なるほど げっ うわ うふ ウン どうぞ おめでとう うしろ うしょう うやむや はて うは えっ おおえ ほら ごめん うぐ いいえ わっ ただいま おやすみ うだ よお こんばんは おさ うか おす こら ごめんなさい へえ ようし まぁ ほんと あゝ さぁ やあ あかん なむ あぁ エッ すみません こりゃ いやいや 南無 はじめまして おーい ういっ 嗚呼 ごめんね ウイ バカヤロー おかえり うおん ごきげんよう へっ おわ ういい う~ うー なるほど! 何だ どっこい うへん ガーン ゴメン ありがと ごめん わんわん はてな うおお すいません お疲れ様 へー ありゃ もしもし 有難う おやすみなさい はぁ うぇ じゃー へぇ ヨロシク もしもし おかえりなさい キャッ
情報量はまあまあといったところでしょうか.出現自体目ずらいしいのであえてストップワードに入れることはあまりしないです.
これ単独で見るとうるさい文章みたいですね.チャットボットとかを作るときに意識的に入れてみるとイキイキしそうです.
連体詞
連体詞のうち,出現頻度上位100語を確認します.
(ノイズ,半角スペース区切り,半角スペースは排除してあります.)
この その 同じ 大きな そのため いわゆる どの こうした そんな ある あらゆる 何らかの そのうち そのほか 単なる どんな さらなる ある時 そのよう いかなる とある そういった こんな 主たる そういう このまま その子 ほんの 我が わが 亡き 聖なる こういう どういう あるとき ある意味 確固たる 当の なんらかの あんな かの 大いなる 大した 其の いろんな 見知らぬ 或 さる 亡き おかしな 如何なる ありとあらゆる さること ふとした わがまま 最たる おなじ まさかの 確たる 名だたる 堂々たる ちいさな さしたる 色んな れっきとした たいした 断固たる 然るべき たっての 微々たる 輝ける 見知らぬ ただならぬ 隠然たる 吾が ろくな おおきな 当の ひょんな事 かの 在りし たんなる とある ひょんな 大きな 小さな きたる 何たる ちっちゃな あくる そのまんま かの ほんの 厳然たる とんだ おおいなる おそるべき こんな 冠たる 由々しき
体言(名詞・代名詞・数詞)を修飾します.これは単語によっては情報量の多いものもあるので「こそあど言葉」のみをストップワードに入れるとよいでしょう.
フィラー
フィラーのうち,出現頻度上位10語を確認します.
(ノイズ,半角スペース区切り,半角スペースは排除してあります.)
と え あ あの あう なんか えー あー えーっと あのー
声の調子を整えたり,何か考えているときに間を埋めるために発する音声を単語化したものです.情報量はほぼないです.音声認識などを使用して獲得した文章や小説などには多く出てくるのでこれもまたストップワードに入れるべきでしょう.対話ボットなどにこれらを入れると人間らしくなるかもしれないですね.
UTF-8の範囲について
はじめに
文字コードの範囲で欲しい情報を抽出したい場合に役立つ情報を書いておきます.
USキーボードにある文字(ASCII)
全体:0x0020 ( (半角スペース)) – 0x007E (~)
数字:0x0030 (0) – 0x0039 (9)
大文字:0x0041 (A) – 0x005A (Z)
小文字:0x0061 (a) – 0x007A (z)
ひらがな
0x3041 (ぁ(小さい あ)) – 0x3093 (ん)
カタカナ
0x30A1 (ァ(小さい ア)) – 0x30F4 (ヴ) もしくは,0x30F3 (ン)
漢字
CJK統合漢字だと,中国,韓国などの漢字も入ってしまうようです.
日本の一般的な環境で扱うことのできる範囲だと以下のようになります.
0x4E00 (一(いち)) – 0x9FD0 (䲤)
最後の方は中国の漢字なので以下の範囲でよいかもしれないです.
0x4E00 (一(いち)) – 0x9FA0 (龠(やく:中国の笛))
常用漢字一覧
範囲で示すのは困難なため,以下の一覧を正規表現などでマッチさせるとよいです.
なお,この一覧はwikipediaの常用漢字一覧に基づいて作成したものです.
亜哀挨愛曖悪握圧扱宛嵐安案暗以衣位囲医依委威為畏胃尉異移萎偉椅彙意違維慰遺緯域育一壱逸茨芋引印因咽姻員院淫陰飲隠韻右宇羽雨唄鬱畝浦運雲永泳英映栄営詠影鋭衛易疫益液駅悦越謁閲円延沿炎宴怨媛援園煙猿遠鉛塩演縁艶汚王凹央応往押旺欧殴桜翁奥横岡屋億憶臆虞乙俺卸音恩温穏下化火加可仮何花佳価果河苛科架夏家荷華菓貨渦過嫁暇禍靴寡歌箇稼課蚊牙瓦我画芽賀雅餓介回灰会快戒改怪拐悔海界皆械絵開階塊楷解潰壊懐諧貝外劾害崖涯街慨蓋該概骸垣柿各角拡革格核殻郭覚較隔閣確獲嚇穫学岳楽額顎掛潟括活喝渇割葛滑褐轄且株釜鎌刈干刊甘汗缶完肝官冠巻看陥乾勘患貫寒喚堪換敢棺款間閑勧寛幹感漢慣管関歓監緩憾還館環簡観韓艦鑑丸含岸岩玩眼頑顔願企伎危机気岐希忌汽奇祈季紀軌既記起飢鬼帰基寄規亀喜幾揮期棋貴棄毀旗器畿輝機騎技宜偽欺義疑儀戯擬犠議菊吉喫詰却客脚逆虐九久及弓丘旧休吸朽臼求究泣急級糾宮救球給嗅窮牛去巨居拒拠挙虚許距魚御漁凶共叫狂京享供協況峡挟狭恐恭胸脅強教郷境橋矯鏡競響驚仰暁業凝曲局極玉巾斤均近金菌勤琴筋僅禁緊錦謹襟吟銀区句苦駆具惧愚空偶遇隅串屈掘窟熊繰君訓勲薫軍郡群兄刑形系径茎係型契計恵啓掲渓経蛍敬景軽傾携継詣慶憬稽憩警鶏芸迎鯨隙劇撃激桁欠穴血決結傑潔月犬件見券肩建研県倹兼剣拳軒健険圏堅検嫌献絹遣権憲賢謙鍵繭顕験懸元幻玄言弦限原現舷減源厳己戸古呼固孤弧股虎故枯個庫湖雇誇鼓錮顧五互午呉後娯悟碁語誤護口工公勾孔功巧広甲交光向后好江考行坑孝抗攻更効幸拘肯侯厚恒洪皇紅荒郊香候校耕航貢降高康控梗黄喉慌港硬絞項溝鉱構綱酵稿興衡鋼講購乞号合拷剛傲豪克告谷刻国黒穀酷獄骨駒込頃今困昆恨根婚混痕紺魂墾懇左佐沙査砂唆差詐鎖座挫才再災妻采砕宰栽彩採済祭斎細菜最裁債催塞歳載際埼在材剤財罪崎作削昨柵索策酢搾錯咲冊札刷刹拶殺察撮擦雑皿三山参桟蚕惨産傘散算酸賛残斬暫士子支止氏仕史司四市矢旨死糸至伺志私使刺始姉枝祉肢姿思指施師恣紙脂視紫詞歯嗣試詩資飼誌雌摯賜諮示字寺次耳自似児事侍治持時滋慈辞磁餌璽鹿式識軸七叱失室疾執湿嫉漆質実芝写社車舎者射捨赦斜煮遮謝邪蛇尺借酌釈爵若弱寂手主守朱取狩首殊珠酒腫種趣寿受呪授需儒樹収囚州舟秀周宗拾秋臭修袖終羞習週就衆集愁酬醜蹴襲十汁充住柔重従渋銃獣縦叔祝宿淑粛縮塾熟出述術俊春瞬旬巡盾准殉純循順準潤遵処初所書庶暑署緒諸女如助序叙徐除小升少召匠床抄肖尚招承昇松沼昭宵将消症祥称笑唱商渉章紹訟勝掌晶焼焦硝粧詔証象傷奨照詳彰障憧衝賞償礁鐘上丈冗条状乗城浄剰常情場畳蒸縄壌嬢錠譲醸色拭食植殖飾触嘱織職辱尻心申伸臣芯身辛侵信津神唇娠振浸真針深紳進森診寝慎新審震薪親人刃仁尽迅甚陣尋腎須図水吹垂炊帥粋衰推酔遂睡穂随髄枢崇数据杉裾寸瀬是井世正生成西声制姓征性青斉政星牲省凄逝清盛婿晴勢聖誠精製誓静請整醒税夕斥石赤昔析席脊隻惜戚責跡積績籍切折拙窃接設雪摂節説舌絶千川仙占先宣専泉浅洗染扇栓旋船戦煎羨腺詮践箋銭潜線遷選薦繊鮮全前善然禅漸膳繕狙阻祖租素措粗組疎訴塑遡礎双壮早争走奏相荘草送倉捜挿桑巣掃曹曽爽窓創喪痩葬装僧想層総遭槽踪操燥霜騒藻造像増憎蔵贈臓即束足促則息捉速側測俗族属賊続卒率存村孫尊損遜他多汰打妥唾堕惰駄太対体耐待怠胎退帯泰堆袋逮替貸隊滞態戴大代台第題滝宅択沢卓拓託濯諾濁但達脱奪棚誰丹旦担単炭胆探淡短嘆端綻誕鍛団男段断弾暖談壇地池知値恥致遅痴稚置緻竹畜逐蓄築秩窒茶着嫡中仲虫沖宙忠抽注昼柱衷酎鋳駐著貯丁弔庁兆町長挑帳張彫眺釣頂鳥朝貼超腸跳徴嘲潮澄調聴懲直勅捗沈珍朕陳賃鎮追椎墜通痛塚漬坪爪鶴低呈廷弟定底抵邸亭貞帝訂庭逓停偵堤提程艇締諦泥的笛摘滴適敵溺迭哲鉄徹撤天典店点展添転塡田伝殿電斗吐妬徒途都渡塗賭土奴努度怒刀冬灯当投豆東到逃倒凍唐島桃討透党悼盗陶塔搭棟湯痘登答等筒統稲踏糖頭謄藤闘騰同洞胴動堂童道働銅導瞳峠匿特得督徳篤毒独読栃凸突届屯豚頓貪鈍曇丼那奈内梨謎鍋南軟難二尼弐匂肉虹日入乳尿任妊忍認寧熱年念捻粘燃悩納能脳農濃把波派破覇馬婆罵拝杯背肺俳配排敗廃輩売倍梅培陪媒買賠白伯拍泊迫剝舶博薄麦漠縛爆箱箸畑肌八鉢発髪伐抜罰閥反半氾犯帆汎伴判坂阪板版班畔般販斑飯搬煩頒範繁藩晩番蛮盤比皮妃否批彼披肥非卑飛疲秘被悲扉費碑罷避尾眉美備微鼻膝肘匹必泌筆姫百氷表俵票評漂標苗秒病描猫品浜貧賓頻敏瓶不夫父付布扶府怖阜附訃負赴浮婦符富普腐敷膚賦譜侮武部舞封風伏服副幅復福腹複覆払沸仏物粉紛雰噴墳憤奮分文聞丙平兵併並柄陛閉塀幣弊蔽餅米壁璧癖別蔑片辺返変偏遍編弁便勉歩保哺捕補舗母募墓慕暮簿方包芳邦奉宝抱放法泡胞俸倣峰砲崩訪報蜂豊飽褒縫亡乏忙坊妨忘防房肪某冒剖紡望傍帽棒貿貌暴膨謀頰北木朴牧睦僕墨撲没勃堀本奔翻凡盆麻摩磨魔毎妹枚昧埋幕膜枕又末抹万満慢漫未味魅岬密蜜脈妙民眠矛務無夢霧娘名命明迷冥盟銘鳴滅免面綿麺茂模毛妄盲耗猛網目黙門紋問冶夜野弥厄役約訳薬躍闇由油喩愉諭輸癒唯友有勇幽悠郵湧猶裕遊雄誘憂融優与予余誉預幼用羊妖洋要容庸揚揺葉陽溶腰様瘍踊窯養擁謡曜抑沃浴欲翌翼拉裸羅来雷頼絡落酪辣乱卵覧濫藍欄吏利里理痢裏履璃離陸立律慄略柳流留竜粒隆硫侶旅虜慮了両良料涼猟陵量僚領寮療瞭糧力緑林厘倫輪隣臨瑠涙累塁類令礼冷励戻例鈴零霊隷齢麗暦歴列劣烈裂恋連廉練錬呂炉賂路露老労弄郎朗浪廊楼漏籠六録麓論和話賄脇惑枠湾腕
便利な正規表現
はじめに
文字コードの範囲でストップワードを指定したりするときに正規表現は強い味方になります.今回は私が良く用いる正規表現をまとめておきます.
日本語に出てくる文字の正規表現
数字,ローマ字,ひらがな,カタカナ,漢字を組み合わせたものです.
自然言語処理系の人の多くはpythonで使うと思うのでpythonのコードで書いておきます.
pythonがわからない方はpatternの右辺のrの隣のダブルクォーテーションの中身を使ってください.
|
1 2 3 |
pattern = r"[0-9A-Za-zぁ-んァ-ヴ一-龠]" if re.match(pattern, text): print(text) |
日本語に出てくる記号の正規表現
よく出てくる記号についてまとめたものです.
必要に応じて上の正規表現と組み合わせて使います.
|
1 2 3 |
pattern = r"[\!-&%\(\)\.\,/=\-,.。、\ ¥’”→↓←↑…「」()ー\ ~『 \・~『』・;:※々ゞヶヵ%]" if re.match(pattern, text): print(text) |
ひらがな1文字と2文字を省く
ひらがな1文字や2文字の単語もどきは形態素解析器の不具合で出てくるものが多いです.
必要なものはホワイトリスト的なものを作って保護しつつ以下のように省きます.
janomeで省くことが多かったのでサンプルはその文脈にしておきます.
よくやりがちなミスですが,文頭を表す^を入れ忘れるとひらがな1文字か2文字含むもの全体を取ってきてしまうので注意が必要です.
|
1 2 3 |
if re.search(r'^[あ-ん]{1,2}$', token.surface): # 処理 pass |
おわりに
今回はストップワードについてまとめてみました.
ここに書いたものなどを組み合わせて,自分が解きたいタスクに特化したストップワードを選定することがシステムの精度の向上につながるでしょう.
また,「名詞,動詞,形容詞のような自立語であるか」や「助詞の前の名詞節」のようなルールと組み合わせるとより強力な前処理が可能になります.
コーパス全体の分析をしてみることも精度の高いストップワードの選定や足切り基準の設定に貢献すると思います.
色々と試してうまくいくまで頑張ってみるとそのうちに感が付いてくると思います.