
執筆:金子冴
今回は,自然言語処理分野で事前処理として用いられることが多い形態素解析に着目し,形態素解析を行う目的や,主要な形態素解析器の比較を行う.また,形態素解析器の1つであるMeCabを取り上げ,インストール方法や実行例,商用利用の注意点等を確認する.また,次回以降の記事にて,MeCabで用いられている以下のアルゴリズムについて解説する.
●bi-gram マルコフモデル(解析モデル)
●CRF(Conditional Random Fields)(学習モデル)
●Viterbi(解探索アルゴリズム)
初めに,形態素解析の概要とメリット,注意点について確認しよう.
目次
形態素解析(Morphological Analysis)とは
形態素解析器(MeCab,JUMAN,その他)の紹介
MeCabのインストールと辞書の追加手順
MeCabの実行例(コマンドライン, Python)
MeCabの商用利用について
MeCabで用いられている代表的なアルゴリズム(次回以降解説)
参考
形態素解析(Morphological Analysis)とは
形態素解析の概要
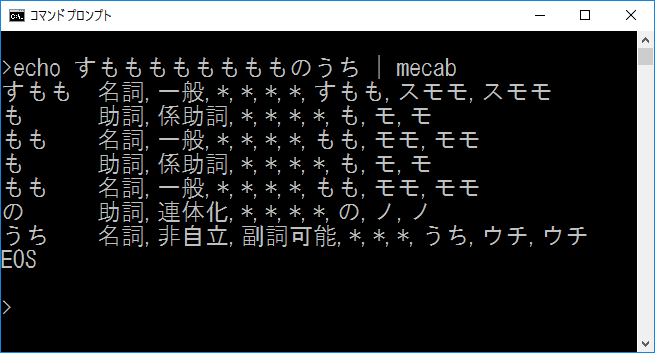
「形態素解析(Morphological Analysis)」とは,自然言語処理分野で主に事前処理として用いられる手法であり,対象となる言語の文法や単語の品詞情報をもとに,文章を形態素(単語が意味を持つ最小の単位)に分解する解析を指す.例えば,「すもももももももものうち」を形態素解析器であるMeCabで解析すると,「すもも も もも も もも の うち」に分解される(実行結果は以下の図のようになる).
形態素解析を行うメリット
文章を形態素解析することで,どのようなメリットが得られるのだろうか.以前紹介した文字列同士,集合同士の類似度計算を行う際には,形態素解析が欠かせない.なぜなら,ある文書を単語ごとに分解しなければ,類似度計算をすることができないからだ.その他にも,Google検索をはじめとする文書検索の分野では,事前に文字列を形態素解析して名詞のみを検索対象とすることで,検索精度の向上と処理データ量の削減を行っている.このように,形態素解析は主処理(類似度計算や文書検索)の事前処理として実施されることが多い.
形態素解析時の注意点
形態素解析を行うにあたって,注意すべきことは「一意にとれない文章も存在する」ことと,「辞書が異なると解析結果が異なる」ことである.それぞれの注意点について,確認しよう.
「一意にとれない文章も存在する」
例えば,「にわにはにわにわとりがいる」という文章を解析するとしよう.最も聞き馴染みのある解析結果は「にわ には にわ にわとり が いる(庭には二羽,鶏がいる)」だろう.しかし,「にわ に はにわ にわ とり が いる(庭にハニワ,二羽,鳥がいる)」とも分解できる.このように,一意にとれない文章については(一意にとれる文章についてもしばしば)意図しない解析結果が出力されることも珍しくないため,注意が必要である.
「辞書が異なると解析結果も異なる」
形態素解析器は,自身の参照する辞書より単語の品詞情報を取得して文字列を解析する.辞書には単語の品詞情報が含まれているが,辞書間で単語の種類や品詞情報が共通化されているわけではない.つまり,別の辞書を使用するとまったく別の品詞情報を用いていることと同じになるため,形態素解析結果が異なる可能性がある.先ほどの例でいえば,辞書に「にわとり(鶏)」が登録されていなければ,前者の解析結果は得られないだろう(「にわとり」は存在しないため,より小さい形態素である「にわ」,「とり」に分解されるはず).
それでは,形態素解析について理解できたところで,実際に形態素解析してくれるツールをざっくり紹介しよう.
形態素解析器(MeCab,JUMAN,その他)の紹介
現在,ありがたいことにオープンソースの形態素解析器が数多く公開されている.
その中でも,今回は主要な形態素解析器であるMeCab,JUMAN,その他について,簡単に紹介する.
MeCabとは
Mecabは京都大学情報学研究科と日本電信電話株式会社コミュニケーション科学基礎研究所の共同研究で開発された形態素解析エンジンである.
言語,辞書,コーパス(データベース化されている言語資料)に依存しない汎用的な設計方針を採用しており,C
言語,C++,Java,python等,数多くの言語で使用することが可能である.また,設定することで様々な辞書を用いることが可能なため,日本語の形態素解析エンジンの中では最もよく使用されている.
[公式サイト]
MeCab: Yet Another Part-of-Speech and Morphological Analyzer
なお,本解説ではMeCabのインストールから辞書の追加方法,実行例を確認する.
JUMANとは
JUMANは京都大学大学院情報学研究科知能情報学専攻の黒橋・河原研究室で開発された形態素解析エンジンである.
使用者によって文法の定義や単語間の接続関係の定義などの変更が容易に行える.
特徴としてUTF-8に対応している点の他に,MeCabよりも単語の意味分類が細かいことが挙げられる.
[公式サイト]
日本語形態素解析システム JUMAN
なお,同研究室で開発されたKNP(係り受け解析器)を使用する際には,JUMANの形態素解析結果を入力として用いる.KNPは係り受け解析によく用いられるため,JUMAN+KNPの組み合わせは覚えておくと良いだろう.
その他の形態素解析器(一部紹介)
詳細な説明は割愛するが,MeCabとJUMAN以外にも数多くの形態素解析器が存在する.以下はその一部だが,使用目的や出力情報を見極め,用途に合ったものを選ぶと良い.
●RakutenMA:JavaScript製の解析器では唯一,学習機能がある.JavaScriptで動作するため,スマホからでもテキスト解析が可能.
●kuromoji:全文検索ソフトウェアのLucene,Solr,elasticsearchに対応.Java,Javascriptで動作.
●KyTea:読みの推定が可能なため,音声認識や音声生成の分野に応用可能.
本解説では,形態素解析器のうちMeCabのwindows10,linux系OSへのインストール手順と辞書の追加,使用例を紹介する.
MeCabのインストールと辞書の追加手順,使用例
MeCabのインストール手順(windows10)
①バイナリパッケージをダウンロード
MeCab公式サイトのdownloadリストのうち,『MeCab本体』のBinary package for MS-Windows mecab-0.996.exeをダウンロードする.

②インストーラを起動
ダウンロードしたexeファイルを起動すると,まず使用する言語を選択できる.今回は日本語でよいだろう.『次へ』で進めていくと辞書の文字コードを選択するウィンドウが表示される.windowsのコマンドプロンプトで設定されている標準文字コードはSHIFT-JISであるが,今回は他OSでも一般的に使用されているUTF-8を選択しよう.
規約に同意したあと,インストール先を指定できる.特に指定がなければ,標準のままC:\Program Files (x86)\MeCabでよいだろう.その後もセットアップの作成等を選択する表示がされるが,特に気にしない場合は変更しなくてよい.『次へ』で進めていくと,MeCabのインストールが開始され,インストールが完了したらコマンドプロンプト上でMeCabを実行できる.バージョン情報は以下のコマンドで確認できる.
|
1 |
mecab --version |
windowsの場合,コンパイル済みのIPA辞書が同梱されているため,この時点で形態素解析が可能である.もし辞書を追する場合は辞書の追加方法(windows)の項目を参考にしていただきたい.辞書の追加はせず,実際にMeCabを使用したい場合はMeCabの使用例を参考にMeCabの使い方を確認してほしい.
MeCabのインストール手順(linux系OS)
今回,linux系OSとしてUbuntuを使用してインストール手順を紹介する.
①tar圧縮されたソースファイルをダウンロード
MeCab公式サイトのdownloadリストのうち,『MeCab本体』のSourcemecab-0.996.tar.gzをダウンロードする.
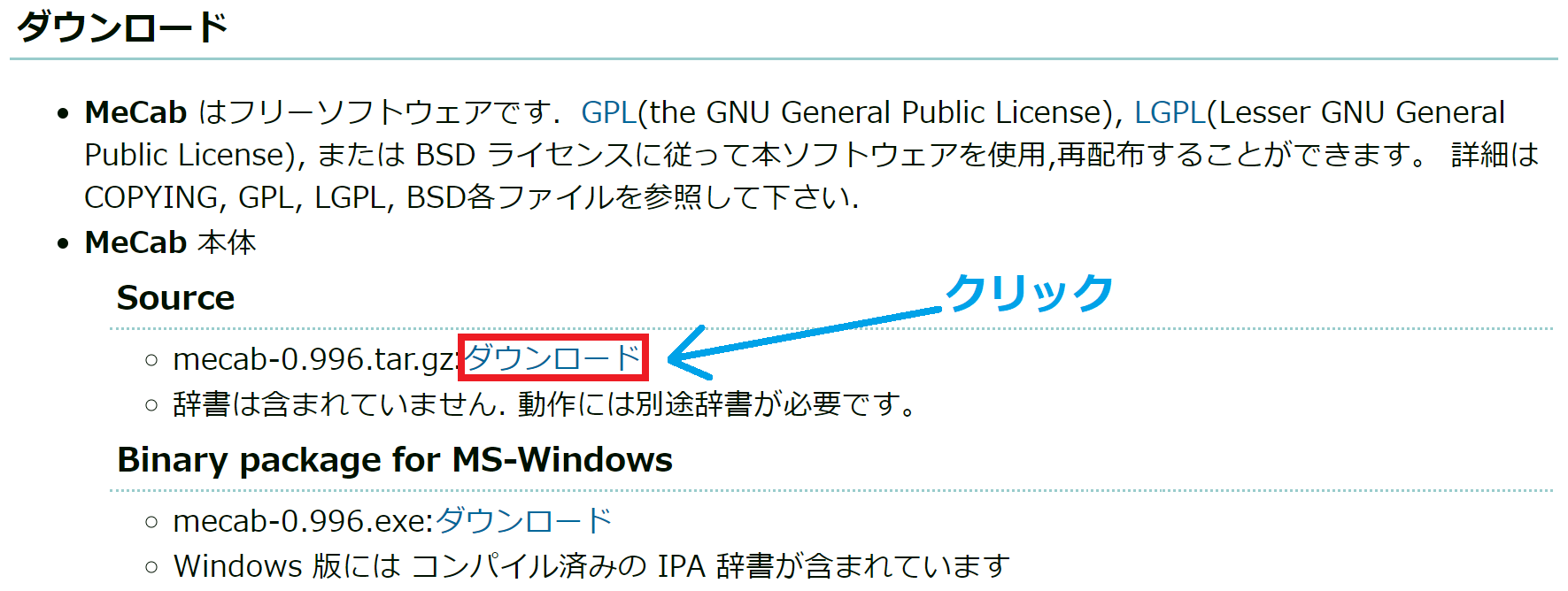
コマンドラインからダウンロードするのであれば,以下のwgetコマンドを実行することで,カレントディレクトリにmecab-0.996.tar.gzという名前で保存できる(保存先や名前を変更する場合は,-Oオプションの引数を『ダウンロード先ディレクトリ+ファイル名』とすること).
|
1 |
wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE" -O "./mecab-0.996.tar.gz" |
なお,先ほどの公式サイトのダウンロードリンクをコピーしてwgetコマンドの引数に指定しただけではダウンロードできないため注意が必要である.Googleドライブからwgetコマンドでファイルを取得する場合は,以下のフォーマットに従ってURLを指定する必要がある.MeCab バージョン0.996のダウンロードリンクからファイルIDを確認したところ,0B4y35FiV1wh7cENtOXlicTFaRUEであった.そのため,上記のwgetコマンドでは,以下のフォーマットの<ファイルID>を0B4y35FiV1wh7cENtOXlicTFaRUEに変更している.
|
1 |
wget "https://drive.google.com/uc?export=download&id=<ファイルID>" |
②ソースファイルを解凍する
①tar圧縮されたソースファイルをダウンロードでダウンロードしたファイルを以下のtarコマンドでカレントディレクトリのmecab-0.996(圧縮ファイルの拡張子を除いた名前)というフォルダに解凍する.tarコマンドの使用方法は割愛する.
|
1 |
tar -xvf mecab-0.996.tar.gz |
③makeファイルを作成する
②ソースファイルを解凍するで解凍先に指定したフォルダ(先ほどのコマンドを実行した場合は『mecab-0.996』)に移動し,configureファイルを使用してMAKEFILEを作成する.今回はインストール先を変更するため–prefixオプションにMeCabインストール先フォルダパスを指定している.これにより,システム全体ではなく自ユーザに対してのみMeCabをインストールできる.自身が管理者でシステム全体にmecabの使用権限を与えたい場合は–prefixオプションを変更する必要はないだろう.他に,今回はデフォルトの文字コードをutf-8にするため–with-charsetオプションにutf-8を指定している.
|
1 2 3 |
cd mecab-0.996 # /path-to-mecabにはMeCabのインストール先フォルダパスを指定 ./configure --prefix=/path-to-mecab --with-charset=utf-8 LDFLAGS=-L/path-to-mecab/lib |
④makeコマンドでビルド,インストール
③makeファイルを作成するでconfigureファイルを使用して作成したMAKEFILEを用いて,makeコマンドからMeCabのインストールを行う.事前に指定したprefix等が正しく設定されているかをチェックしたい場合は,MAKEFILEを確認するとよい.
|
1 |
make && make install |
⑤環境変数PATHとLD_LIBRARY_PATHの設定
makeコマンドによるインストールが完了したら,最後に環境変数PATHとLD_LIBRARY_PATHの設定を行う.一時的に使用する場合は以下のコマンドを実行すればよいが,その場合は現在使用しているターミナルのみでしか設定は反映されない.次回ログイン以降や別ウィンドウのターミナルでも使用したい場合は./bashrc(使用しているシェルによって異なる)等の設定ファイルに同じ文章を追記すればよい.追記した後は,設定ファイルを反映することでPATHとLD_LIBRARY_PATHが更新される.
|
1 2 3 |
# /path-to-mecabにはMeCabのインストール先フォルダパスを指定 export PATH="/path-to-mecab/bin:$PATH" export LD_LIBRARY_PATH="/path-to-mecab/bin:$LD_LIBRARY_PATH" |
ここまででMeCabのインストールは完了である.試しに以下のコマンドを実行しすると,バージョン情報が表示されるだろう.
|
1 |
mecab --version |
![]()
辞書の追加方法(windowsの事前準備)
今回はwindows向けバイナリファイルに同梱されているIPA辞書ではなく,固有表現や新語が豊富に含まれているmecab-ipadic-NEologdを辞書に追加し,IPA辞書と併用してみよう.なお,NEologdはshift-jisに対応していないため,MeCabをshift-jisで使用する場合は自分でコンパイルする必要がある.コンパイルの際は,以下のサイトを参考にするとよい.
MeCab-ipadic-neologdをshift-jisでコンパイルする
本解説では事前に辞書の文字コードにutf-8を指定しているため,NEologdも同様にutf-8で追加する.親切にもNEologdの公式GitHub(日本語版README.md)にwindows10へのインストール方法が紹介されているため,これを参考にインストールを進めていこう.
①Windows Subsystem for Linuxのインストール
公式GitHubでは,まずwindows環境にBash on Windowsをインストールすると記載されている.しかし,windows10ではこのBash on Windowsに代わるソフトウェアであるWindows Subsystem for Linuxというソフトウェアが8月にリリースされており,インストール作業が大きく簡略化されている.そのため,今回はWindows Subsystem for Linuxを使用する.また,インストール手順についてもすでにわかりやすいサイトが存在するため,こちらを参考にインストールしていただきたい.
Windows Subsystem for Linuxをインストールしてみよう!
Windows Subsystem for Linuxのインストールが完了したら,windows標準のコマンドプロンプトを起動し,『bash』と打ち込んでWindows Subsystem for Linuxが起動できるか確認してみよう.
②インストールに必要なパッケージをインストール
Windows Subsystem for LinuxがインストールできたらNEologdのインストールに必要なライブラリを事前にインストールする.公式GitHubではaptitudeコマンドを使用しているが,このコマンドは標準では入っていないため,初めにaptコマンド(使用方法は割愛)を使用してaptitudeをインストールする.なお,これ以降のコマンドは断りがあるまでWindows Subsystem for Linux上で実行してほしい.
|
1 2 3 4 5 6 7 8 9 |
sudo apt-get update # パッケージリストの更新 sudo apt-get upgrade # インストール済パッケージの更新(updateするかを確認されるためYを入力) sudo apt-get aptitude # aptitudeのインストール sudo aptitude update # パッケージリストの更新(aptitude) sudo aptitude upgrade # インストール済パッケージの更新(aptitude)(updateするかを確認されるためYを入力) sudo aptitude install make automake autoconf autotools-dev m4 mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file # NEologdのインストールに必要なパッケージをインストール sudo sed -i -e 's%/lib/mecab/dic%/share/mecab/dic%' /usr/bin/mecab-config # 辞書格納先のパスを置換 |
これ以降はlinux系OSと同じ作業を行うため,しばらく(辞書の追加方法(windows反映)まで)このまま読み進めてほしい.
辞書の追加方法(windows,linux系OS)
ここからは辞書のインストール作業を行う.
①ソースコードをGitHubからダウンロード
希望するダウンロード先に移動して以下のコマンドを実行するとmecab-ipadic-neologdという名前でフォルダが作成され,その中にGithub上のソースコードがダウンロードされる.
|
1 |
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git |
②NEologdのインストール
①ソースコードをGitHubからダウンロードで作成されたmecab-ipadic-neologdフォルダに移動し,./bin/installフォルダ内のinstall-mecab-ipadic-neologdを実行してNEologdをインストールする.その際,インストール先を指定しなかった場合はmecab-configで指定されている場所にインストールされるため,linux系OS向けの項目を読み進めてきた読者で③makeファイルを作成するにてインストール先を–prefixオプションで変更した読者は,ここでも–prefixオプションで辞書のインストール先をMeCabのインストール先のディレクトリ階下に指定するとよいだろう(例:/path-to-MeCab/dic/mecab-ipadic-neorogd).
|
1 2 3 4 |
# -nオプションで最新の辞書を取得(初回でも必要) # MeCabのインストール先を変更している場合は--prefixオプションでNEologdのインストール先を # MySQLのディレクトリ階下に指定するとよい ./bin/install-mecab-ipadic-neologd -n --prefix /path-to-NEolodg |
これでlinux系OSでのNEologdのインストールは完了である.windows環境への辞書追加は後続の作業があるため,次の項を読み進めてほしい.また,MeCabの実行時にNEologdを使用する場合は特別にオプションを指定する必要があるため,全員の読者にはMeCabの実行例の項目は必ず読んでいただきたい.
辞書の追加方法(windowsの事後作業)
windowns環境で辞書を追加する場合,②NEologdのインストールでインストールしたNEologdをローカル環境のMeCabフォルダ内に移動しなければならない.Windows Subsystem for Linuxを使用している場合/mnt/cディレクトリにローカル環境のCドライブがマウントされているため,cpコマンドでコピーするだけでよい.しかし,②インストーラを起動にて,アクセスに管理者権限が必要なフォルダ(標準インストール先のC:\Program Files (x86)\MeCab等)をインストール先に指定している場合は,subsystem環境から直接コピーすることができない.そのため以下のコマンドのように,ホームディレクトリ階下のDocumentフォルダに一時的にコピーし,windows上でDocumentフォルダからMeCabのインストール先にフォルダを移動するとよい.
|
1 2 3 |
# NEologdをインストールしたフォルダをローカルのDocumentフォルダにコピー # Documentフォルダにコピー後,手作業でMeCabのインストール先に移動する cp /path-to-NEologd-on-subsystem /path-to-windows-local-document-path |
windowsについても,これで辞書の追加が完了した.次の項からは実際にMeCabを使用して形態素解析をしてみよう.IPA辞書とNEologdの併用を指定する方法についても紹介する.
MeCabの実行例(コマンドライン,Python)
MeCabをコマンドライン上で実行
初めに,コマンドライン上でMeCabを実際に使用する方法を解説する.以下は,mecabを起動して「私の朝食はパンでした」という文章を形態素解析した結果である.
|
1 2 3 4 5 6 7 8 9 10 |
mecab # MeCabの起動 私の朝食はパンでした 私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ の 助詞,連体化,*,*,*,*,の,ノ,ノ 朝食 名詞,サ変接続,*,*,*,*,朝食,チョウショク,チョーショク は 助詞,係助詞,*,*,*,*,は,ハ,ワ パン 名詞,一般,*,*,*,*,パン,パン,パン でし 助動詞,*,*,*,特殊・デス,連用形,です,デシ,デシ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ EOS |
MeCabの-Oオプション解説
自然言語処理分野で解析をする場合,単語での分割はしたいが,品詞情報は不要という場面もあるだろう.単語分割のみを行うことを一般にわかち書きというが,MeCabでわかち書きをする場合は-Oオプションにwakatiを指定するとよい.-Oオプションでは他にも読み付与やChasen互換などが指定できる.以下に,先ほども挙げた文章をわかち書きした結果を載せる.
|
1 2 3 |
mecab -O wakati # MeCabの起動(わかち書き) 私の朝食はパンでした 私 の 朝食 は パン でし た |
辞書を併用して形態素解析
次に,以下の例を見てほしい.これは,MeCab標準のIPA辞書で「昨日は『君の名は。』を観に行ったよ」という文章を形態素解析した結果である.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
mecab # MeCabの起動 昨日は『君の名は。』を観に行ったよ 昨日 名詞,副詞可能,*,*,*,*,昨日,キノウ,キノー は 助詞,係助詞,*,*,*,*,は,ハ,ワ 『 記号,括弧開,*,*,*,*,『,『,『 君 名詞,代名詞,一般,*,*,*,君,キミ,キミ の 助詞,連体化,*,*,*,*,の,ノ,ノ 名 名詞,一般,*,*,*,*,名,ナ,ナ は 助詞,係助詞,*,*,*,*,は,ハ,ワ 。 記号,句点,*,*,*,*,。,。,。 』 記号,括弧閉,*,*,*,*,』,』,』 を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 観 名詞,一般,*,*,*,*,観,カン,カン に 助詞,格助詞,一般,*,*,*,に,ニ,ニ 行っ 動詞,自立,*,*,五段・カ行促音便,連用タ接続,行く,イッ,イッ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ よ 助詞,終助詞,*,*,*,*,よ,ヨ,ヨ EOS |
ここで注目してほしいのは「君の名は。」が「君 / の / 名 / は / 。」と分解されている点である.「君の名は。」は2016年に公開された大ヒット映画の題名であるが,MeCab標準の辞書には「君の名は。」という単語が登録されていないため,より小さな単位で分解されているのである.分析を行うにあたって,意味のある新語や固有表現を1つの単語として抽出することはとても重要である.そこで,新語や新しい固有表現に強いNEologdと標準のIPA辞書を併用して「君の名は。」を1つの単語として抽出できるかを確認しよう.辞書を追加する際は-dオプションで辞書をインストールしたフォルダのパスを指定すればよい.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
mecab -d /path-to-NEologd # MeCabの起動(辞書追加) 昨日は『君の名は。』を観に行ったよ 昨日 名詞,副詞可能,*,*,*,*,昨日,キノウ,キノー は 助詞,係助詞,*,*,*,*,は,ハ,ワ 『 記号,括弧開,*,*,*,*,『,『,『 君の名は。 名詞,固有名詞,一般,*,*,*,君の名は。,キミノナハ,キミノナハ 』 記号,括弧閉,*,*,*,*,』,』,』 を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 観 名詞,一般,*,*,*,*,観,カン,カン に 助詞,格助詞,一般,*,*,*,に,ニ,ニ 行っ 動詞,自立,*,*,五段・カ行促音便,連用タ接続,行く,イッ,イッ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ よ 助詞,終助詞,*,*,*,*,よ,ヨ,ヨ EOS |
NEologdとIPA辞書を併用した結果,「君の名は。」が1単語で名詞として抽出できている.形態素解析は自然言語処理分野で事前処理として使用されることが多いが,解析結果が望むものと異なる場合,主処理が正常に動作しても有効な結果が得られないこともある.形態素解析を行う場合は,どの辞書を使用するかについても入念に事前調査する必要があるだろう.
Python(3系)からの使用例
使用例の最後の項目として,自然言語処理分野でよく使われるPython(3系)からMeCabを実行する手順を簡単に紹介する.
①mecab-python3をインストール
PythonからMeCabを使用するために,事前にmecab-python3というパッケージをインストールする.インストールにはpipコマンドを用いるとよい.
|
1 |
sudo pip install mecab-python3 |
②Pythonから実行
Pythonから使用する場合は,以下のように記述するとよい.-Oオプションや辞書の併用方法などはコマンドライン上と同じ書き方のため,必要であればMeCab.Tagger()メソッドの引数として渡す.以下の例ではNEologdを併用するため,-dオプションを指定している.
|
1 2 3 4 5 6 7 8 9 10 11 |
import MeCab str = "となりの隣がとなりのトトロ" tagger = MeCab.Tagger("-d /path-to-NEoligd") print(tagger.parse(str)) # となり 名詞,一般,*,*,*,*,となり,トナリ,トナリ # の 助詞,連体化,*,*,*,*,の,ノ,ノ # 隣 名詞,一般,*,*,*,*,隣,トナリ,トナリ # が 助詞,格助詞,一般,*,*,*,が,ガ,ガ # となりのトトロ 名詞,固有名詞,一般,*,*,*,となりのトトロ,トナリノトトロ,トナリノトトロ EOS |
MeCabの商用利用について
MeCabでは2018年7月現在,GPL,LGPL,BSDの3ライセンスを採用している.MeCabの公式サイトにも記載されている通り,ライセンスの詳細は詳細は COPYING, GPL, LGPL, BSDの各ファイルに記載されているため,それらのファイルを確認していただきたい.ここでは,それぞれのライセンスがどういうものなのかを確認しよう.
GPL(GNU General Public License)とは
まず,GNUプロジェクトについて説明する.GNUプロジェクトとはフリーソフトウェア マス・コラボレーション(複数の人が独立して1つのプロジェクトに取り組むこと) プロジェクトである.GPLは,そのGNUプロジェクトのために作成されたフリーソフトウェアライセンスで,フリーソフトウェアに対してプログラムの実行,動作の調査,改変,複製物の再頒布,プログラムの改良,リリースする権利を許諾するライセンスである.
重要な点のみ抜き出すと,このライセンスはMeCabに対する改変,再頒布を許諾している.また,GPLは二次的著作物に対しても上記の4つの権利を保護する.つまりGPLでライセンスを受けた著作物の二次的著作物も,GPLでライセンスされなければいけないため,MeCabを使用して作成したプロダクトは改変や再頒布が可能になってしまう.そのため,ユーザに見えないような内部のロジックに使用を限定する等の対応が必要である.
LGPL(GNU Lesser General Public License)とは
こちらも名前にGNUとついていることから,GNUプロジェクトのために作成されたフリーソフトウェアライセンスであることがわかるだろう.ただし,こちらはフリーソフトウェアではなく他のソフトウェアと組み合わせて使用されるソフトウェアやライブラリに対してライセンスされる.GPLとの違いをもとに,LGPLを確認しよう.
GPLは二次的著作物に対してもGPLでライセンスされることを義務としていた.これに対してLGPLはLGPLでライセンスされたソフトウェアやライブラリのソースコードをプログラムに組み込んだ場合,二次的著作物もLGPLでライセンスすることが義務になっている.つまり,ソースコードの開示等が義務付けられる.対して,LGPLでライセンスされたソフトウェアやライブラリのソースコードをプログラムに組み込まない場合,二次的著作物はLGPLでライセンスする必要はない.MeCabで例えるなら,MeCabのソースコードを流用,改変してプログラムを作成した場合はLGPLでライセンスを受ける必要があり,MeCabをモジュールとして使用するプログラムを作成した場合はLGPLでライセンスを受ける必要はないということになる.
BSD(BSD License)とは
BSDには他のライセンスと違い,3つの種類が存在するため注意が必要である.元々,BSDはソースコードの再配布条件,バイナリ形式の再配布条件,機能に言及,使用する宣伝物への謝辞記載義務,貢献者の情報開示範囲の限定を定めたライセンスであった.この4条件を定めたBSDライセンスは4-clause BSD licenseと呼ばれる.また,4条件のうち「機能に言及,使用する宣伝物への謝辞記載義務」を除いたBSDライセンスを3-clause BSD license,さらにそこから「貢献者の情報開示範囲の限定」を除いたBSDライセンスを2-clause BSD licenseと呼ぶ.どのBSDライセンスが適用されているかを事前に調査しておくことが重要である.なお,MeCabでは3-clause BSD licenseを採用している.
MeCabで用いられている代表的なアルゴリズム(次回以降解説)
次回以降,MeCabの公式サイトで記載されている情報を参考に,内部で使用されている以下のアルゴリズムを解説する.
●bi-gram マルコフモデル(解析モデル)
●CRF(Conditional Random Fields)(学習モデル)
●Viterbi(解探索アルゴリズム)
【2018/07/13追記】
それぞれの記事を公開しております.
【技術解説】bi-gramマルコフモデル
【技術解説】CRF(Conditional Random Fields)
【技術解説】HMMに基づいたViterbiアルゴリズムによる解推定手法(例題つき)
参考
・形態素解析とは
・形態素解析とは?おすすめの5大解析ツールや実際の応用例を紹介
・意外にあった!?日本語の形態素解析ツールまとめ
・日本語形態素解析の裏側を覗く!MeCab はどのように形態素解析しているか
・MeCab: Yet Another Part-of-Speech and Morphological Analyzer
・日本語形態素解析システム JUMAN
・日本語構文・格・照応解析システム KNP
・curlやwgetで公開済みGoogle Driveデータをダウンロードする
・MeCab-ipadic-neologdをshift-jisでコンパイルする
・Windows Subsystem for Linuxをインストールしてみよう!
・[Ubuntu] apt-get まとめ
・商用利用できるオープンソースライセンスはけっきょくどれで何をすればいいのか?
・LGPL【ライセンス】
・LGPLの概要