SCROLL

自然言語処理技術を活用して、業務のコスト改善&新規事業機会を創出したい企業様向けに、ミエルカで培ってきた自然言語処理・機械学習の技術をつかった、 文章解析/生成/推薦アルゴリズムのAPI提供をしています。自然言語処理・機械学習(人工知能)の機能を自社サービスに 取り入れたい企業様に最適です。
■運用の流れ
大量の文章からニーズを含む文章を抽出し ます.アンケート結果やWebページなどか ら,どのようなことが求められているかを 抽出できます.
サイト回遊率を増やす手助けをします.AIが 自動で,サイト内のページから関係のあり そうで踏んでくれそうなページへのリンク を提案します.
Web上のコピーコンテンツを監視し検知し ます.自社のコンテンツが真似されていな いか,ライターがコピペで記事を作ってい ないかが判定できます.

人工知能(AI)の一分野である「自然言語処理」を応用し、検索ユーザーのニーズを抽出・分析、評価されやすいコンテンツづくりを的確に支援するWebマーケティングツール。クラウド上で「自社サイトの改善すべきページの抽出」「ライバルサイトとの差異の発掘」など、主にWebコンテンツ改善に活用できる機能が豊富。
SEE DETAILS
ミエルカヒートマップは、サイト流入後の来訪ユーザーの行動を可視化し、WEBサイトのボトルネックをわかりやすく色分けで判別する事が可能なサービスです。
無料からお試しすることができ、リリース依頼数千のお客様にご活用いただいております。
人工知能・機械学習・自然言語処理周辺の技術情報のメディアを運営しています。
基礎的な技術の解説から、ビジネス応用まで様々な方に向けて記事を展開しています。
SEE DETAILS
ストップワードの除去は自然言語処理やテキストマイニングにおける重要な作業です. 解析の精度を上げるために不要な記号や単語を等をデータセットから除去します. ストップワードの選定にはタスクに特化した分析が必要ですが,ある程度整理されているデータがあるととても助かります. そこで,今回は私が自然言語処理のタスクでよく行う,日本語のストップワードについてまとめました. また単語の分布などから,品詞ごとのストップワードに対する考察も行いました. このことからストップワードを介して自然言語処理のあまり語らることのない知識などをご共有できればと思います. (この記事の考察部分は主に自然言語処理の初心者を対象とした入門記事です.) 目次 1. 自然言語処理・ストップワードとは 2. 分析の対象 3. 単語の分布に対する考察 ┣ 出現頻度 上位300件 ┗ 出現頻度と単語 4. 品詞ごとに考察 ┣ 名詞 ┣ 動詞 ┣ 副詞 ┣ 助詞 ┣ 接続詞 ┣ 記号 ┣ 助動詞 ┣ 感動詞 ┣ 感動詞 ┗ 連体詞 5. 便利な正規表現 ┣ ひらがな ┣ カタカナ ┣ 漢字 ┗ 常用漢字一覧 6. おわりに 自然言語処理・ストップワードとは 自然言語処理… Read More »
The post 【自然言語処理入門】日本語ストップワードの考察【品詞別】 appeared first on ミエルカAI は、自然言語処理技術を中心とした、RPA開発・サイト改善・流入改善レコメンドエンジンを開発.
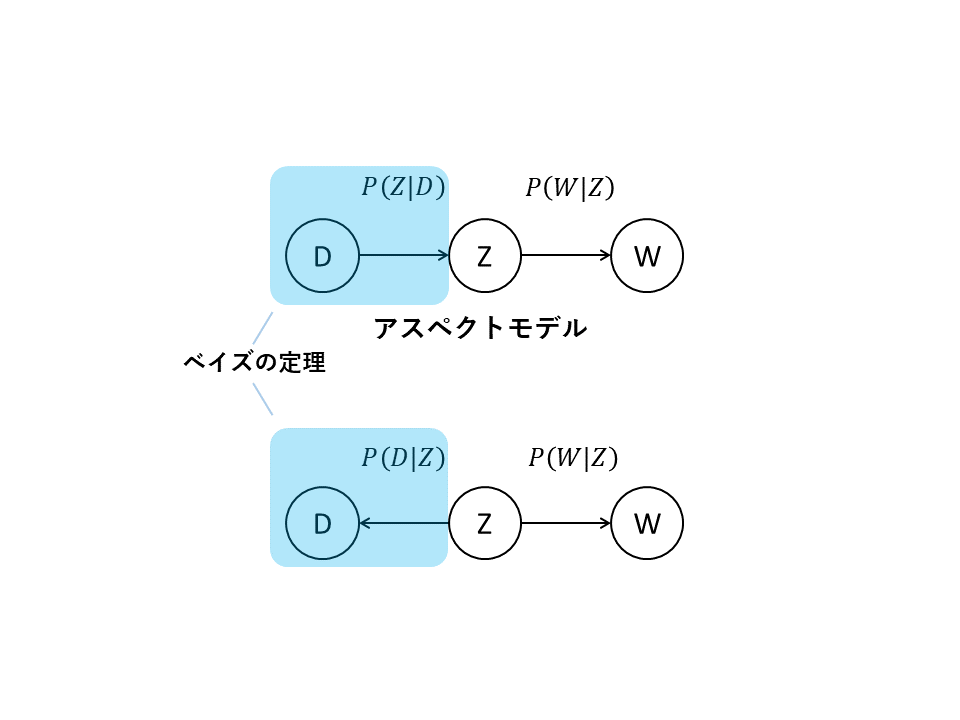
今回は潜在意味解析(Latent Semantic Analysis: LSA)を確率的に発展させたトピックモデルの確率的潜在意味解析(PLSA)について解説します. このモデルを使うと潜在的な意味をトピックとして抽出でき,そのトピック内で単語と文書が出現する確率がわかります.主に既存のデータの分析に用いられています. 目次 確率的潜在意味解析(PLSA)とは PLSAのアルゴリズム PLSAの学習 EMアルゴリズム (E-step) EMアルゴリズム (M-step) 過学習の対策 (TEM) LSAとPLSAの比較 PLSAでの分析例 PLSAの応用 PLSAの問題点 参考文献 確率的潜在意味解析(PLSA)とは 確率的潜在意味解析(Probabilistic Latent Semantic Analysis: PLSA)とは,1999年にHofmannらが発表したトピックモデルの代表例である.トピックモデルは,文書は複数の独立した潜在的なトピックから成るものとして,その過程を確率分布を用いてあらわした確率モデルである. 例えば,「車中泊」についての文章は「自動車」や「キャンプ」などのトピックからなると考えられる.「自動車」から単語「車」,「車内」,「座席」が生成され,「キャンプ」から単語「泊まる」,「水」,「自炊」,「寝る」が生成されたとする.その場合「車中泊」についての記事の単語群(BOW)は{車, 車内, 座席, 泊まる, 水, 自炊}となる.トピックモデルでは一般的に語順は考慮されない.この場合に生成される文書の例として「車に泊まるとき,車内で自炊ができるように水を持っていくとよいでしょう.また車内で寝られるよう座席がフルフラットにできる車を選びましょう.」があげられる.実際には「動詞」や「助詞」を表すトピックもここには入っている. トピックモデルを用いる場合,文章を生成することよりもその単語や文書がどのトピックから生成されたのかに焦点を当てることの方が多い.そのため,先ほど例に挙げた文書を解析し,トピック「自動車」や「キャンプ」などを得たり,トピック「自動車」において「車」や「座席」はどれほど影響を与えるのかなどについて分析を行う. PLSAのアルゴリズム PLSAのアルゴリズムを解説していく. 用いる記号 単語:$W = \{w_1,w_2,…,w_M\}$ 文書:$D = \{d_1,d_2,…,d_N\}$ トピック:$Z = \{z_1,z_2,…,z_K\}$ 単語と文書の同時確率 $$ \displaystyle \begin{eqnarray} P(D, W) &=& P(D)P(W|D) \\ &=&… Read More »
The post 【技術解説】確率的潜在意味解析(PLSA)のアルゴリズムと応用 appeared first on ミエルカAI は、自然言語処理技術を中心とした、RPA開発・サイト改善・流入改善レコメンドエンジンを開発.
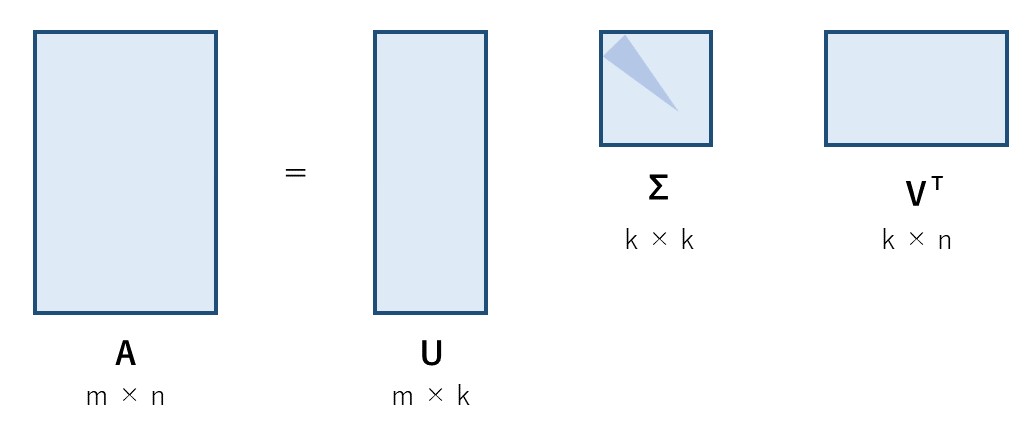
今回は潜在意味解析(Latent Semantic Analysis: LSA)と特異値分解(Singular Value Decomposition: SVD)について解説します. LSAは文書の分類や,情報検索の分野(この分野ではLSIとして知られる)などに使われるトピックモデルの代表例として知られています. このモデルを使うと,単語と文書のそれぞれの組み合わせについて,類似度を測れるようになります. 目次 潜在意味解析(LSA, LSI)とは 特異値分解(SVD) LSAのアルゴリズム LSAの応用 LSAの問題点 参考文献 潜在意味解析(LSA, LSI)とは 潜在意味解析(Latent Semantic Analysis: LSA)とは,1990年にDeerwesterらが発表した,文章の自動インデックス化,検索の方法である.検索の分野では潜在意味インデックス(Latent Semantic Indexing: LSI)とも呼ばれる.高次元の文書群から,与えられたクエリに意味的に関連する文書を見つけてくるために作られた.単語-単語,単語-文書,文書-文書の類似度を求めることができる. この手法では高次元の文書の行列を,特異値分解(SVD)という線形代数的手段で低次元に縮約し用いている.圧縮されてできたベクトル空間内では,近い概念は近くに,遠い概念は遠くにプロットされる.低次元に縮約することによって,疎らなデータやノイズが多いデータに対応できる.また,メモリに乗らない巨大なデータにも対応できる. 時代的背景 LSA以前の時代に作られた情報検索の手法では,語の意味そのものに着目していた.しかし,語の意味は多義語として知られるように,文脈によって変わることもあり信用性に欠ける.また,単語Aで検索した時にその類義語の単語Bの結果もある程度考慮しなくてはならないが,これに対応するのに困難していた.そのため,より信頼性の高いエンティティの集合に置き換える必要があるとLSAの提案者たちは考えていた. 特異値分解(SVD) LSAのアルゴリズムのうち大切な部分がこの特異値分解(SVD)である.まずは,この技術について解説していく. 特異値分解(SVD)とは 特異値分解(Singular Value Decompositon: SVD)とは一言でいうと上の図のように,任意の実行列が二つの直交行列と特異値からなる対角行列の内積に分解できるということである. $$ \displaystyle A = UΣV^T $$ 右辺の,左右の行列($U$と$V^T$)の各列をそれぞれ,右特異ベクトル,左特異ベクトルと呼ぶ.また,それぞれ入力の行,列ベクトルの張る空間の正規直交基底を表す.ここで,行列$A$の特異値とは,$A$とその随伴行列$A^{*}$(複素共役かつ転置行列)であるとの積のそれぞれの固有値における,非負の平方根のことである.つまり,真ん中の行列$Σ$の対角成分の二乗は固有値である.特異値は各基底の重要度を表している. (LSAの論文中では,$X = T_{0}S_{0}D_{0}^{*}$と記されている.T:term, S:semantic space, D:documentを表していると思われる.) SVDの証明概略 以下の式が成り立つことを示す. $$A = UΣV^T$$ 任意の$m×n(m\geq… Read More »
The post 【技術解説】潜在意味解析(LSA) ~特異値分解(SVD)から文書検索まで~ appeared first on ミエルカAI は、自然言語処理技術を中心とした、RPA開発・サイト改善・流入改善レコメンドエンジンを開発.

東京大学 工学部 システム創成学科(PSI)卒業。卒業後はITベンチャー畑を 歩み、株式会社SOOL元取締役CMO/SOOL パートナー(現任)。2014年エン・ジャパン社への事業売却を行い、ミエルカの開発に参画。言語解析、クローリングなどを強みとする。

ロンドン大学(UCL)、早稲田大学大学院(化学専攻)卒業。ウェブアナリストとしてマイクロソフト、サイバーエージェント、アマゾンジャパン等で勤務。2015年、当社CAO就任(現任)。解析ツールの導入・運用・教育、ゴール&KPI設計、施策の実施と評価、PDCAを社内で回すための取り組みなどを担当。

筑波大学ビジネスサイエンス系准教授(現任)。2006年に有限会社てっくてっくを創業、2021年より現職。ウェブのコンテンツやユーザの行動に注目し、自然言語処理や計算社会科学に関する研究に従事。ウェブ・SNSの大規模なデータ収集や分析・機械学習を強みとし、Best in Practice Paper Award(WI-IAT '21)など数々の賞を受賞。

明治大学 理工学部 情報科学科 教授(現任) 。計算型人工知能の世界トップレベルの研究者であると同時に、マーケティングにも詳しい。近年では、言語計算、プロファイリング、ソーシャルデータ解析、推薦エンジン、データドリブンマーケティングなどの研究に従事。
会社概要
※ 撮影場所:WeWork神谷町トラストタワー| 会社名 | 株式会社Faber Company ※「ファベルカンパニー」と読みます。 |
|---|---|
| 所在地 |
[東京本社] |
| 資本金 | 1億円 |
| 設立 | 2005年10月24日 |
| 役員 |
【経営陣】
【当社顧問】
【共同研究】
|
| 事業紹介 |
【サービス一覧】
【情報発信サイト】 |