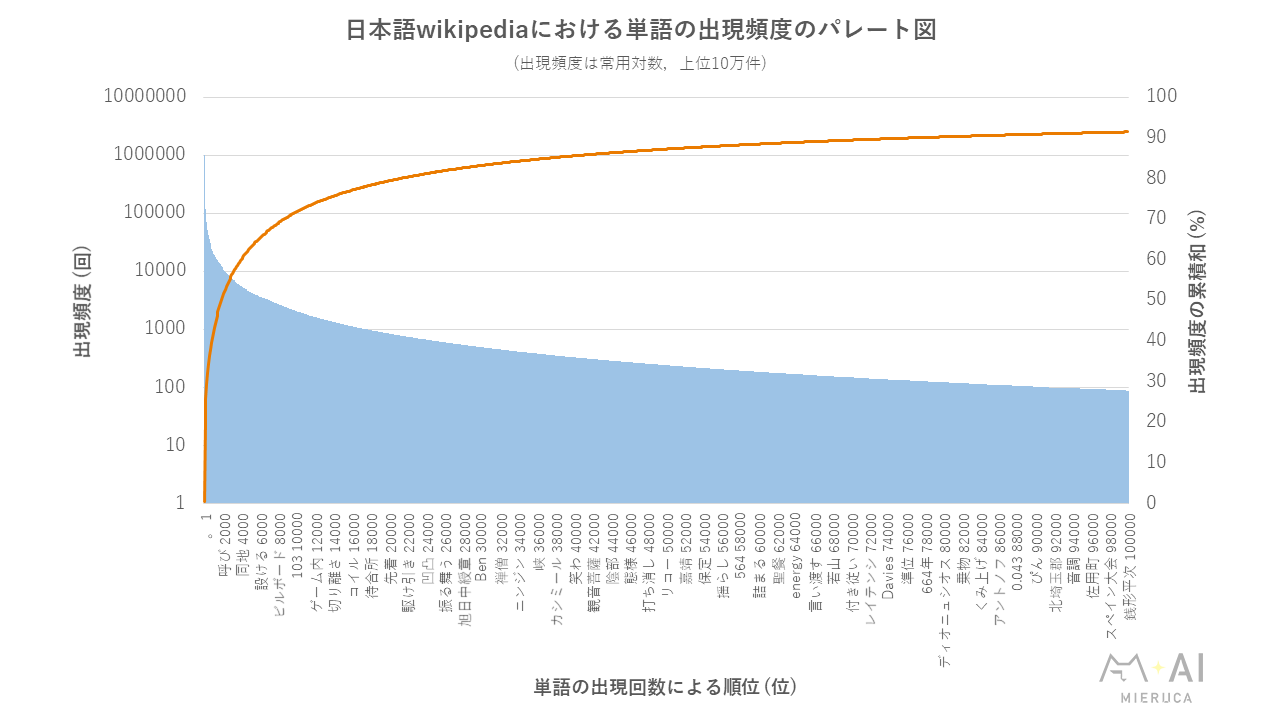
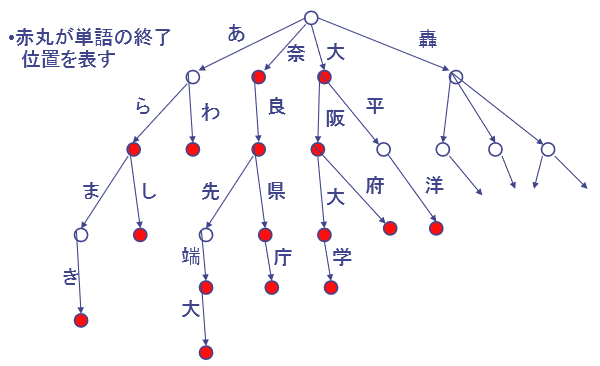
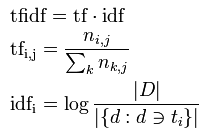ストップワードの除去は自然言語処理やテキストマイニングにおける重要な作業です.
解析の精度を上げるために不要な記号や単語を等をデータセットから除去します.
ストップワードの選定にはタスクに特化した分析が必要ですが,ある程度整理されているデータがあるととても助かります.
そこで,今回は私が自然言語処理のタスクでよく行う,日本語のストップワードについてまとめました.
また単語の分布などから,品詞ごとのストップワードに対する考察も行いました.
このことからストップワードを介して自然言語処理のあまり語らることのない知識などをご共有できればと思います.
(この記事の考察部分は主に自然言語処理の初心者を対象とした入門記事です.)
技術解説
研究ブログ
自然言語処理
非エンジニア向け
【自然言語処理入門】日本語ストップワードの考察【品詞別】