執筆:金子冴
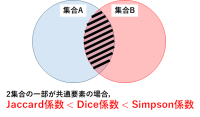
前回の記事(【技術解説】似ている文字列がわかる!レーベンシュタイン距離とジャロ・ウィンクラー距離の計算方法とは)では,文字列同士の類似度(距離)が計算できる手法を紹介した.また,その記事の中で,自然言語処理分野では主に文書,文字列,集合等について類似度を計算する場面が多いことについても触れた.今回は集合同士の類似度を表現する以下の3つの係数と計算方法について解説する.
●Jaccard係数
●Dice係数
●Simpson係数
その前に,自然言語処理で類似度を表す指標について確認しよう.