
第1回では、テキストマイニングの前段階となる形態素解析の仕組みから形態素解析を用いた行列化(BoW)などの基本事項について説明致しました。第2回では、行列化したテキストデータからどのように知見を取り出すかという話ができればと思います。
第1回でも簡単に触れましたが、行列化したテキストデータに対して統計的手法を用いることで、知見を抽出することができます。テキストマイニングの手法は多くあるのですが、今回は
- TF-IDF法
⇒文書群から特徴語を抽出する方法として用いられる。 - LSI法
⇒文書間距離や単語間距離を計算する際に、次元圧縮する方法として用いられる。(BoWは文書数の増大に伴い非常に大きなサイズの行列になるため、単語の情報を知りたいときは文書の情報を100~200次元へ圧縮してその後の分析を行なうというケースが多い。) - LDA法
⇒文書をトピックという抽象概念の構成比で数値化するための手法として用いられる。
の3つのテキスト解析の手法について、第2回では解説します。
以下、本稿の目次です。
1. 前回の振り返り、BoW(Bag of Words)に関して
前回の話で、BoWの具体例をご紹介しましたので、それを元に振り返りたいと思います。
以下が元文書です。
| ◆元文書文書1 私の名前はジョンだ。文書2 私は車を買った。ジョンはそれを羨ましげに見ている。文書3 ジェファーソンは私に対して腹を立てている。 |
以上の3つの文章があった際に、それぞれの文に対してMeCabを用いて形態素解析を行うと、
| ◆形態素解析後文書1 私|の|名前|は|ジョン|だ|。|文書2 私|は|車|を|買っ|た|。|ジョン|は|それ|を|羨まし|げ|に|見|て|いる|。|文書3 ジェファーソン|は|私|に対して|腹|を|立て|て|いる|。| |
のようになります。図1はこの形態素解析結果をBoWの形に変換したものです。(助詞、助動詞は意味をなさないことが多いのでここでは一度省きました。)
 図1 BoW変換後
図1 BoW変換後
このように作成したBoWという文書と単語の行列を用いて、以下22節から44節で述べる様々な統計解析の手法を行います。
2-1. TF-IDF理論
tf-idfは、文書中の単語に関する重みの一種であり、主にある文書集合に含まれる文書A、における特徴語を抽出する目的で使用されます。
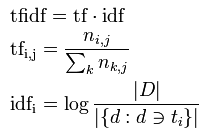
{kind=link}
図2はTF-IDFの数式です。ここでni,jは、文書iにおける単語jの出現頻度、|D|は総ドキュメント数、|{d:d∋ti}|は単語iを含む総ドキュメント数を表しています。言葉で置き換えると、
TF : 単語がどのくらい多く含まれているか
IDF : 単語が含まれている文書がどのくらい希少か
を表しています。
2-2. TF-IDFの具体例・応用例
言葉で説明しただけではわかりにくいので、先ほどの図2のBoWを用いて文書1におけるTF-IDFを考えてみます。
※文書1では、「私」、「名前」、「ジョン」がそれぞれ1回ずつ、合計3単語です。
「私」は3つの文書全てで出現しています。「名前」は文書1のみ、「ジョン」は文書1と文書2の2つの文書で出現しています。これらをもとに、TFとIDFを計算します。
|
TF(私) : 1/3 = 0.33..IDF(私) : log(3/3) = 0TFIDF(私) : TF(私)×IDF(私) = 0TF(名前) : 1/3 = 0.33..IDF(名前) : log(3/1) = 1.09..TFIDF(名前) : TF(名前)×IDF(名前) = 0.366… TF(ジョン) : 1/3 = 0.33.. IDF(ジョン) : log(3/2) = 0.40.. TFIDF(ジョン): TF(ジョン)×IDF(ジョン) = 0.13… |
したがって、図1の例では「名前」という単語が特徴的に使用されていると読み取ることができます。この例ではTFは「私」、「名前」、「ジョン」のどれも同じ値を示している一方で、IDFが全ての文書で使われている「私」が0であるのに対し、文書1でしか使用されていない「名前」が1.09となっています。そのためTFIDFのスコアが高いものに注目することで、文書1で特徴的に使用されている「名前」を抽出することが可能になります。
TF-IDFを応用することで多数の文書があった時に、その中の一部の文書の中で特徴的に使用されているキーワードを抜き出すことができます。
これを利用して作成が可能なサービスとしては、
- 特徴語抽出システム
- 文書間類似度計算システム
などが考えられます。
3-1. LSIの理論
Wikipediaに詳しい説明が載っていたため、数式を用いた説明は省略しますが、以下理論の背景や目的について述べます。
LSIは図1のようなBoWにおいて主成分分析という考え方を用いて行か列の数を減らす手法です。LSIが必要となる背景としては、図1のように文書数や単語数が少ないうちはよいのですが、文書数や単語数が増えてくると取り扱いが面倒になったり傾向が把握しにくくなったりしてしまい、何らかの形で抽象化を行う必要があるというのがあります。
3-2. LSIの具体例
3-1で紹介した理論や背景の記述だけでは、LSIは結局どのようなことをするのかがわかりにくいと思いますので、以下具体的にホットワインに関する検索結果から14記事ピックアップしてLSI分析を行なってみた過程と結果についてまとめます。
ファイルの順番に関しては、
- BoW
- 文書の情報を圧縮した結果(2次元、Excelシート)
- 単語の2次元へのマッピング
の順に配置をしています。BoWから文書の情報を圧縮し2次元で表す過程にLSIという手法が使用されています。
BoW
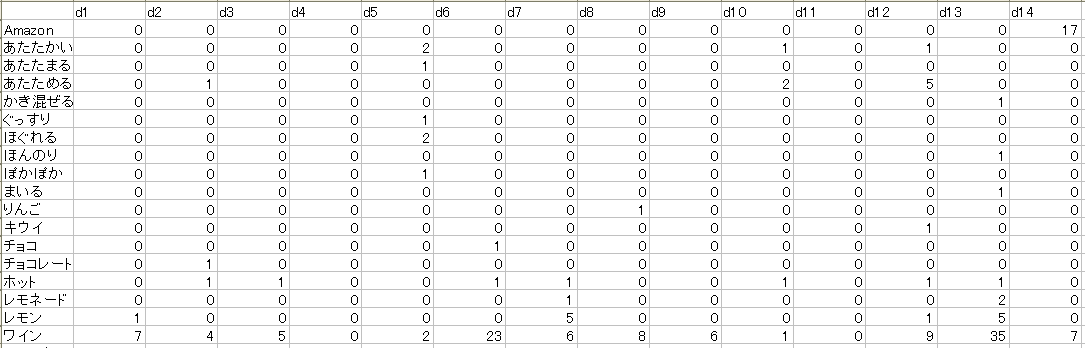
BoWの結果の読み方に関しては、前回記事の例でもご紹介したので詳しくは省略しますが、ここでは縦方向が単語、横方向が文書(14記事)を表しています。
文書の情報を圧縮した結果(2次元、Excelシート)
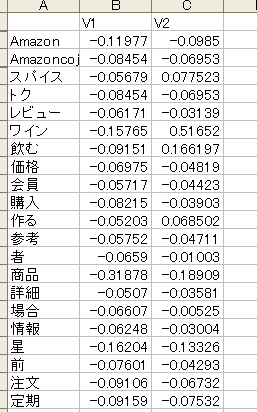
上図はLSIという手法を用いることで、14次元あった文書の情報を2次元に圧縮したものです。
※14次元であればまだ必ずしも圧縮する必要のある規模ではありませんが、例としてはこのくらいの分量の方がよいと思いましたので、一旦この規模で具体例を紹介しました。無論、2次元にすることでマッピングが可能になるので、その意味では圧縮する意味があります。
単語の2次元へのマッピング
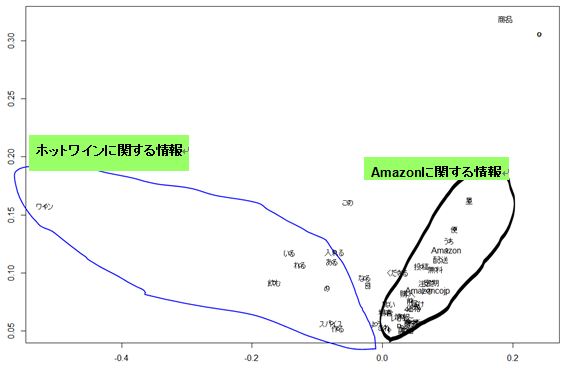
上図は圧縮結果を2次元に圧縮したものを、図にプロットした結果です。(単語数が2000を越えており、全て表示するには限界があったので、絶対値の小さい単語は省きました。)今回の結果では、ホットワインに関する情報とAmazonに関する情報が大まかにグルーピングできました。Amazonが出てきたのは、14記事のひとつにホットワインがAmazonで紹介されているページがあったため、Amazon関連の単語が表示されるという結果になりました。
このようにLSIを用いる事により情報の圧縮をすることが可能です。
冒頭でも述べましたが、BoWは情報量が爆発することが多いのでこのような次元圧縮の手法は必須となります。とはいえ、次元圧縮のイメージがつかないと思いますので、3-3節で近年話題のword2Vecを紹介しながら次元圧縮のイメージをつかんでいただければと思います。
3-3. LSIの応用 word2Vec
LSIを似たような考えに基づいて作成されたシステムとして、最近話題のword2Vecがあります。(実際にword2vecはLSIだけを使っているわけではないようなのですが、次元圧縮という考え方自体は近いものがあるかと思います。また、LSIを使用することで擬似的なword2Vecの作成を行なう事は可能だと思います。)
word2Vecの原理としては、
http://tjo.hatenablog.com/entry/2014/06/19/233949
がわかりやすいです。要するに単語を100次元~200次元でベクトル表現をするというものです。単語を100~200次元でベクトル表現しているということは、単語を100~200個の指標で表しているということです。たとえば、「王様」であれば、
性別:男性
役割:偉い、国のトップ
政治形態:専制政治
のように、いくつかの指標で表すことができます。
これにより、
“king” + “woman” – “man” = “queen”
などが可能になり、単語の意味解析が可能になります。
4-1. LDAの理論
LDAの原理は難しいので、理論の説明は省きます。興味のある方は以下参考書籍をご紹介させていただきますので、こちらのご確認をお願い致します。
 http://www.amazon.co.jp/トピックモデルによる統計的潜在意味解析-自然言語処理シリーズ-佐藤一誠/dp/4339027588
http://www.amazon.co.jp/トピックモデルによる統計的潜在意味解析-自然言語処理シリーズ-佐藤一誠/dp/4339027588
LDAの概要としては、前述のBOWは単語と文書インデックスの関係だったのに対し、単語と文書インデックスの間にトピックという抽象的な概念を挟むことで文書をトピックという抽象概念で表す事ができるということです。
4-2. LDAの具体例
概要のところで述べただけではわかりにくいと思いますので、具体的に説明させていただきます。以下、実際にLDA分析を行った時の具体例のファイルを元に解説させていただきます。
この分析の元データとしては、
- 経済系の記事(econo) 16記事
- 技術系の記事(tech) 15記事
- 食べ物系の記事(food) 18記事
- キャリア系の記事(carrer)12記事
- 趣味系の記事(hobby) 13記事
の計74記事に対してLDAを行った結果です。LDAを行う際のパラメータであるトピックの数は10で行いました。
以下結果の説明です。
◆単語とトピックのファイルに関して
図3が単語とトピックに関してのLDAの結果を加工したものになります。
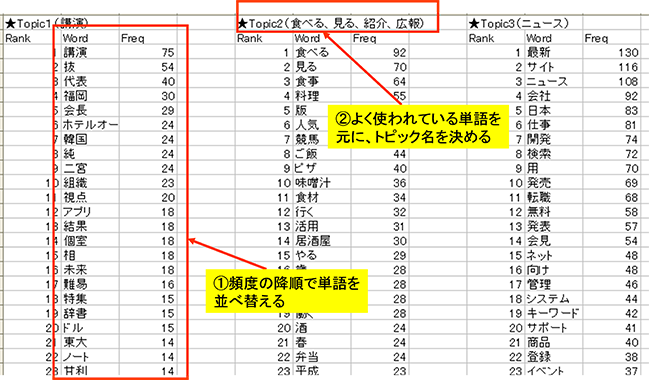 図3 単語とトピック
図3 単語とトピック
図のような手順で、各トピックの名付けを行います。ここで名づけを行ったトピックを元に文書に関して分析を行います。
◆文書とトピックのファイルに関して
図4が文書とトピックに関してのLDAの結果を加工したものになります。
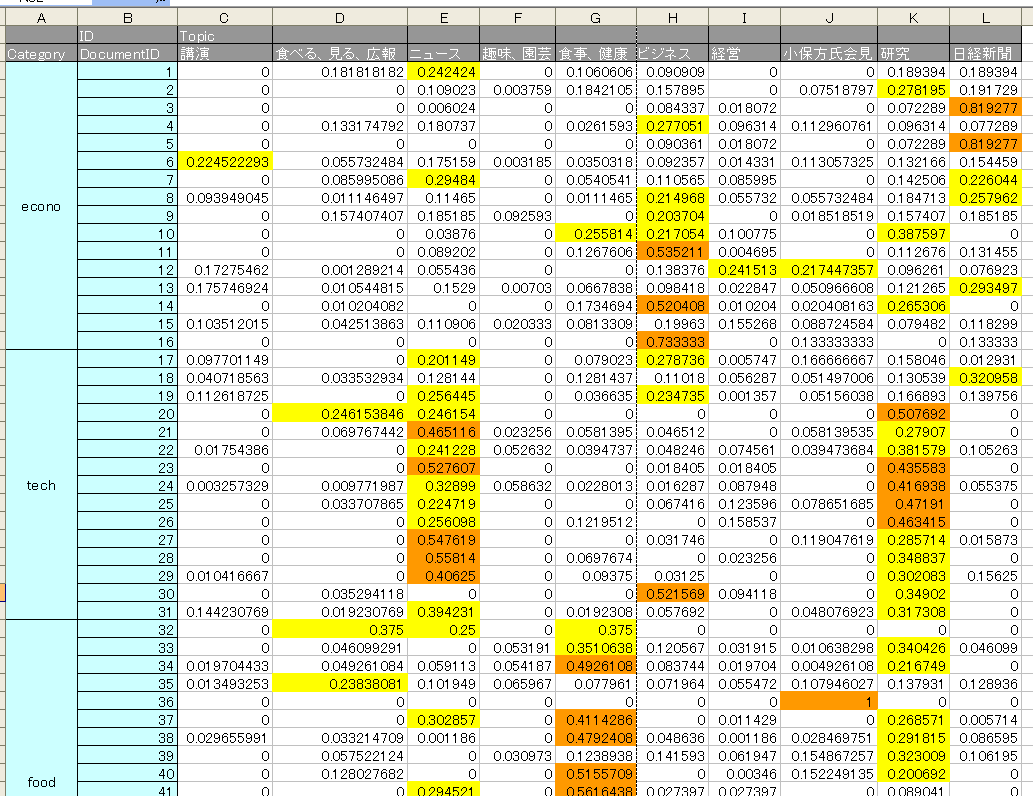 図4 文書とトピック
図4 文書とトピック
図より、経済系(econo)の記事は「ニュース系トピック」、「ビジネス系トピック」、「日経新聞系トピック」の3つのトピックで成り立っており、技術系(tech)記事は「ニュース系トピック」と「研究トピック」で成り立っている事がわかります。また、食事系(food)の記事は「食事、健康系のトピック」で主に成り立っていました。
以上のように、LDAを用いる事により、文書をトピックという抽象概念の構成比で表す事ができるようになります。
5. まとめ
以下が、第2回のまとめです。
- テキストマイニングはBoWを元に分析を行なう
- TF-IDFは特徴語抽出のために用いられる
- LSIは次元圧縮のために用いられる
- LDAは文書をトピックという抽象概念の構成比で表すために用いられる
いかがでしたでしょうか、もしかしたらいささか難解な話が続いてしまったかもしれません。
次回は、第1回・第2回でまとめたテキストマイニングの知見を元に検索エンジンのアルゴリズムに対して迫りたいと思います。それでは引き続きよろしくお願いします。
[writer-mieruca]