
執筆:金子冴
今回は,形態素解析器であるMeCab,Chasen,JUMANで解探索アルゴリズムに採用されているViterbiアルゴリズム(Viterbi algorithm)について解説する.
目次
Viterbiアルゴリズム(Viterbi algorithm)とは
Viterbiアルゴリズムの推定手順
Viterbiアルゴリズムの推定手順(例題)
Viterbiアルゴリズムの応用可能性
参考
Viterbiアルゴリズム(Viterbi algorithm)とは
アルゴリズムの解説にうつる前に,まずは概要を理解しよう.
Viterbiアルゴリズムの概要
“ビタビアルゴリズム(英: Viterbi algorithm)は、観測された事象系列を結果として生じる隠された状態の最も尤もらしい並び(ビタビ経路と呼ぶ)を探す動的計画法アルゴリズムの一種であり、特に隠れマルコフモデルに基づいている。” – ビタビアルゴリズム(wikipedia)
上記の概要を見るに,Viterbiアルゴリズムを理解するためには事前に動的計画法と隠れマルコフモデル(HMM)について理解する必要がありそうだ.後者の隠れマルコフモデルについては当ブログですでに取り扱った題材のため,そちらをご覧いただきたい.
⇒マルコフモデルと隠れマルコフモデル
それでは,動的計画法について確認していこう.
動的計画法(Dynamic Programming)とは
「Viterbiアルゴリズムは動的計画法アルゴリズムの一種」とwikipediaの概要には記載してあるが,そもそも動的計画法とは何なのだろうか.wikipediaを確認してみよう.
“動的計画法(どうてきけいかくほう、英: Dynamic Programming, DP)は、計算機科学の分野において、アルゴリズムの分類の1つである。対象となる問題を複数の部分問題に分割し、部分問題の計算結果を記録しながら解いていく手法を総称してこう呼ぶ。” – 動的計画法(wikipedia)
具体的には,以下の2条件を満たすアルゴリズムを動的計画法と呼ぶ.
◆分割統治法
分割統治法では,大きな問題を小さな問題に分割し,分割後の小さな問題をすべて解決することで最終的に大きな問題を解決する.一般的には小さな問題に分解したあと再帰によって個別に問題を解決していくが,同じ問題を複数回解決する必要がある場合などに計算コストが著しく増加する恐れがある.その問題を防ぐ方法として,もう1つの条件であるメモ化を利用する.
◆メモ化
メモ化とは,一度計算した結果を保持しておくことで同じ問題の再計算を不要とする手法である.メモ化により計算量が削減されることで,プログラムの高速化や最適化が可能となる.
動的計画法については別の記事でより詳細に解説する予定のため,今回は上記の説明にとどめる.
次に,Viterbiアルゴリズムの目的について確認しよう.
Viterbiアルゴリズムの目的
Viterbiアルゴリズムの目的は,wikipediaにも記載されている通り観測された出力から最も尤もらしい状態系列を推測することである.Viterbiアルゴリズムでは,その最も尤もらしい状態系列をビタビ経路と呼ぶ.
ご存じのとおり,隠れマルコフモデルでは状態が隠れている.Viterbiアルゴリズムでは,遷移確率と出力確率,出力結果から,その隠された状態の系列を推測することが目的となる.
それでは,Viterbiアルゴリズムによる状態系列の推定手順を確認しよう.
Viterbiアルゴリズムの推定手順
推定手順を確認する前に,いくつか変数を定義しよう.
今回,推定に用いる隠れマルコフモデルをMとし,Mの出力系列をoT=o1,…,oTとする.oTを出力するような状態遷移系列は複数あることが一般的であるが,その中から確率的に最も尤もらしい状態遷移系列を推定することがViterbiアルゴリズムの目的となる.これは,状態遷移系列をqT=q1,…,qTとした時,出力系列が出力される確率P(oT,qT|M)が最大となるような状態遷移系列qTを求めるということである.
時刻tで状態qiに到達する状態遷移系列に関して,最大の確率値をδt(i)とする.このとき,状態毎に存在するδt(i)は以下の式で表される.この式の右辺はモデルMにおいて,状態qt-1から状態qtに遷移し,かつotが出力されるような状態qt-1の中で最も高い確率値を返す.なお,式中のXtは現在の状態を表す.
δt(i)を再帰的に計算するため,Viterbiアルゴリズムでは以下の式を用いる.なお,式中のaijは状態qiから状態qjへの遷移確率,bj(ot+1)は状態qjにおけるot+1の出力確率を表す.
また,最後に状態遷移系列を復元するため,最大の確率値δt+1(j)を与える直前の状態をψ(・)に記憶しておく.
それでは,Viterbiアルゴリズムの推定手順について確認しよう.手順には大きく分けて「初期化」「再帰処理」「再帰終了後処理」「最適状態系列の復元」の4つの段階がある.
1.初期化
まず,t=1の時の状態qi(i=1,2,…,N)における変数δ,ψについて以下のように初期化を行う.なお,πiは状態qiの初期状態確率(状態qiが初期状態となる確率)である.このことから,δ1(i)は,各状態qiについて初期状態かつo1が出力される確率となることがわかるだろう.
2.再帰処理
時刻t=1,…,T-1として,状態qj(j=1,…,N)の最大の確率値δt+1(j)を再帰的に計算する.また,最大の確率値δt+1(j)を与える直前の状態iを記憶するψについても更新する.
余談だが,max[f(x)]はf(x)を最大にするxを返し,argmax[f(x)]はf(x)を最大にするxの集合を返す.
3.再帰終了後処理
再帰処理は時刻t=T-1で終了するため,最後に時刻t=Tにおける最大の確率値Pと状態遷移系列qTを計算する.
4.最適状態系列の復元
3.再帰終了後処理までの手順で得られた状態遷移系列qTについてt=T-1,…,1の順に以下の式を用いて最適状態系列を獲得する.
以上が,Viterbiアルゴリズムの推定手順である.数式のみではわかりづらい部分もあると思うので,例題と図を用いて再度手順を確認してみよう.
Viterbiアルゴリズムの推定手順(例題)
それでは,Viterbiアルゴリズムの推定手順で確認した手順を,例題に当てはめて再度確認しよう.
今回,「John has fried chicken for dinner」という英文の品詞情報を推定する問題を考える.対象の英文の品詞系列(状態遷移系列)には名詞-動詞-形容詞-名詞-前置詞-名詞(訳:ジョンは夕食にフライドチキンを食べる)と名詞-動詞-動詞-名詞-前置詞-名詞(訳:ジョンは夕食のためにチキンを揚げている)の2パターンが考えられる.今回は,下図のような隠れマルコフモデルを用いて,どちらの品詞系列が尤もらしいかを確率的に求めてみよう.
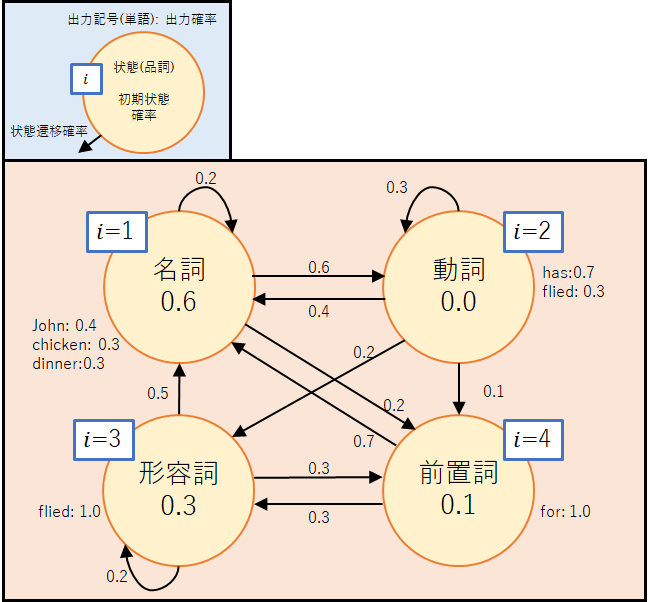
では,推定手順に沿って確認していこう.
1.初期化(例題)
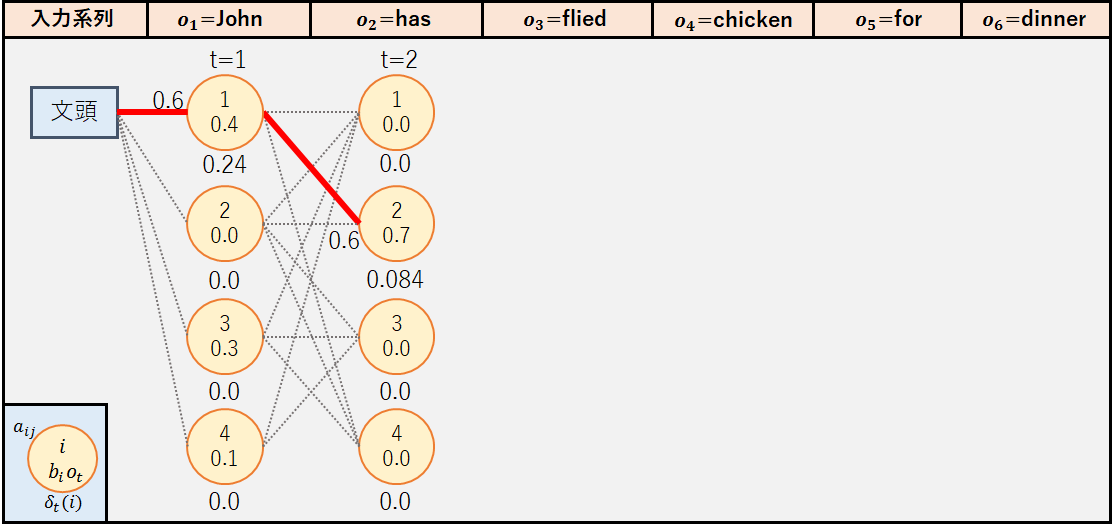
まず,すべての状態qiについて,δ1(i)とψ1(i)を初期化する.今回はo1=”John”である.
この時の経路図は以下のようになる.図中で[文頭]から状態1に伸びている赤線は,状態毎の最大の確率値をとる経路を表している.なお今回は図を見やすくするため,最大の確率値が0.0である状態へのパスについては赤線を記載していない.例えば,状態2ではo1=”John”の出力確率が0であることから最大の確率値は0.0となるため,パスはグレーの点線となっている.

2.再帰処理(例題)
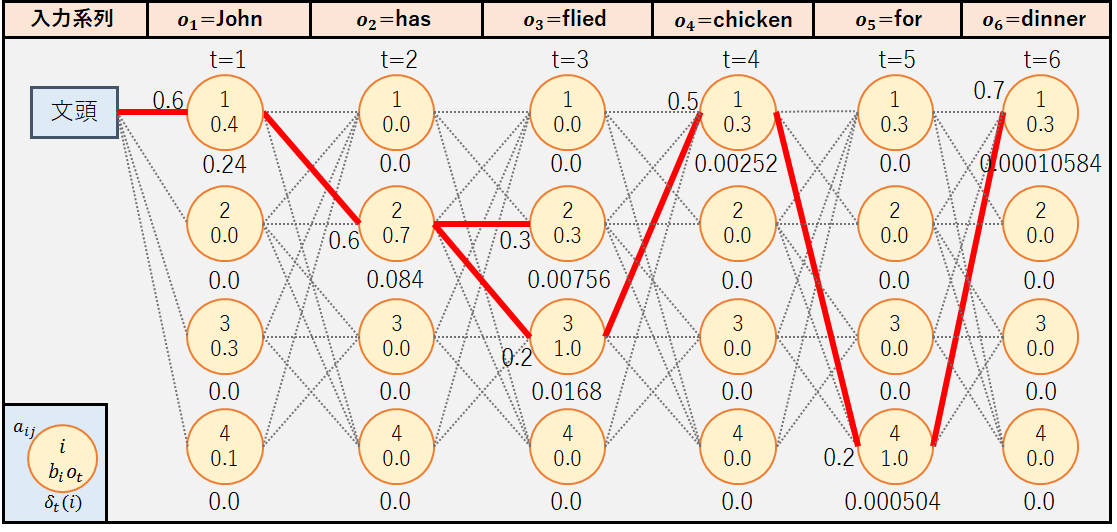
初めに,今回の例題で再帰処理を行った後の経路図を載せておく.つまり,手順通りに経路を推定した場合,状態遷移系列qTは{1,2,3,1,4,1}=名詞-動詞-形容詞-名詞-前置詞-名詞となるはずである.それでは,手順に沿って経路図を作成してみよう.
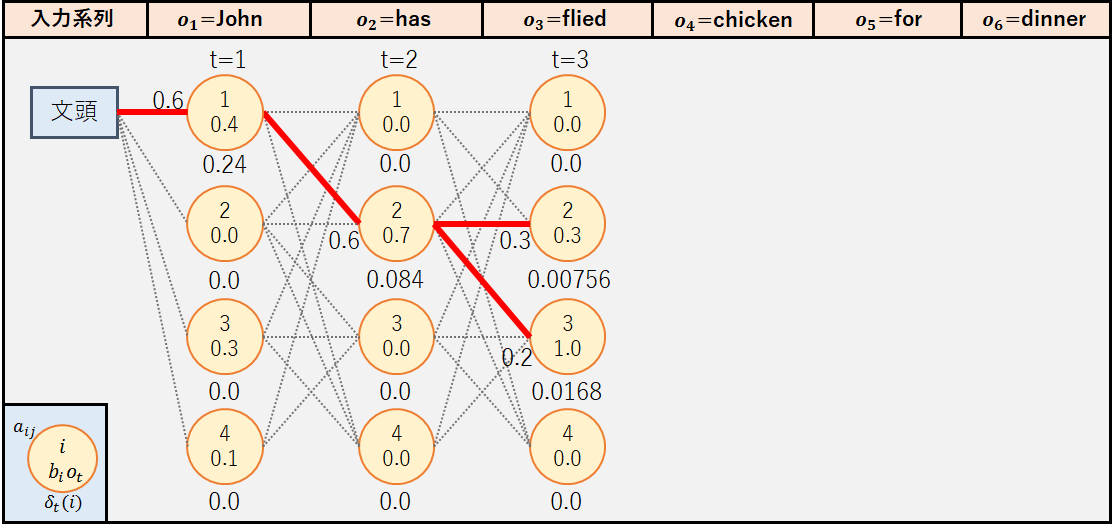
①t=1(o2=”has”)
今回は簡略化のため,最大の確率値が0.0である状態についてはψt(j)を保持しないこととする.
◆j=1
出力確率b1(o2)が0のため,δ2(1)=0.0
◆j=2
◆j=3
出力確率b3(o2)が0のため,δ2(3)=0.0
◆j=4
出力確率b4(o2)が0のため,δ2(4)=0.0
②t=2(o3=”fried”)
◆j=1
出力確率b1(o3)が0のため,δ3(1)=0.0
◆j=2
◆j=3
◆j=4
出力確率b4(o3)が0のため,δ3(4)=0.0
③t=3(o4=”chicken”)
◆j=1
◆j=2
出力確率b2(o4)が0のため,δ4(2)=0.0
◆j=3
出力確率b3(o4)が0のため,δ4(3)=0.0
◆j=4
出力確率b4(o4)が0のため,δ4(4)=0.0
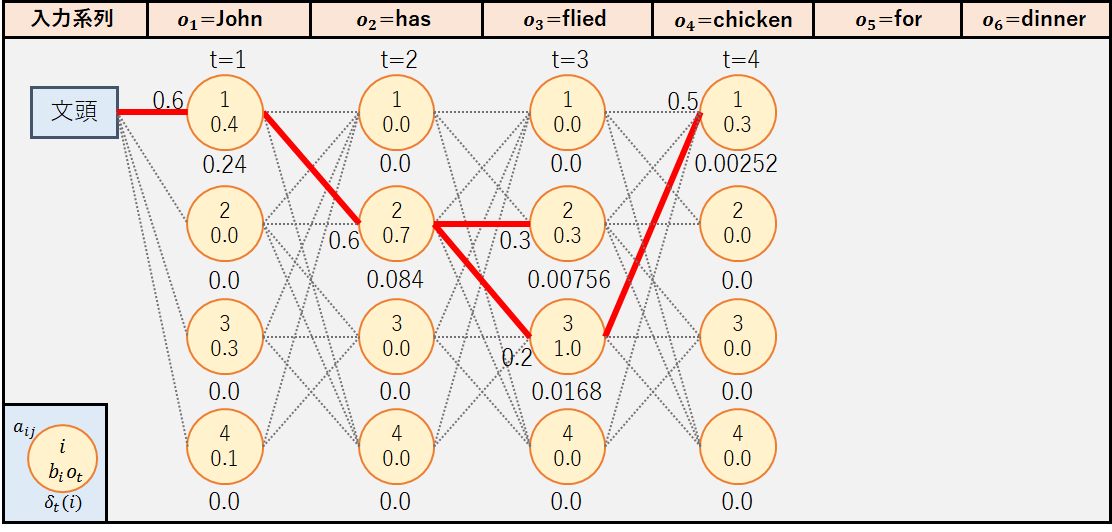
ここで注目してほしいのは,状態q2ではなく状態q3からのパスが採用された点である.これはo3=”fried”が動詞よりも形容詞である確率が高いと推定されたことを表している.
④t=4(o5=”for”)
◆j=1
出力確率b1(o5)が0のため,δ5(1)=0.0
◆j=2
出力確率b2(o5)が0のため,δ5(2)=0.0
◆j=3
出力確率b3(o5)が0のため,δ5(3)=0.0
◆j=4
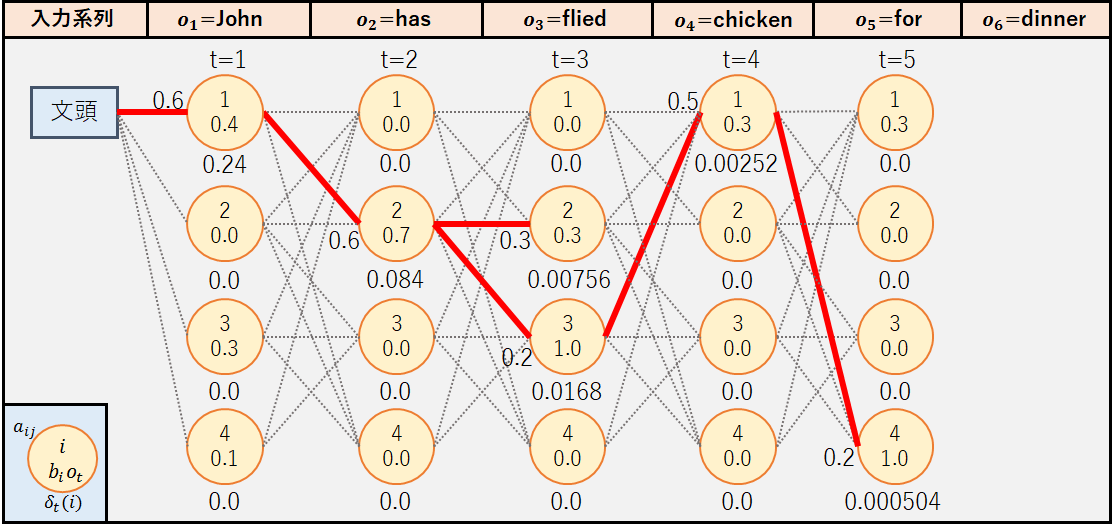
⑤t=5(o6=”dinner”)
◆j=1
◆j=2
出力確率b2(o6)が0のため,δ6(2)=0.0
◆j=3
出力確率b3(o6)が0のため,δ6(3)=0.0
◆j=4
出力確率b4(o6)が0のため,δ6(4)=0.0
3.再帰終了後処理(例題)
2.再帰処理(例題)でt=T-1=5まで再帰処理を行ったため,t=T=6における最大の確率値Pと状態系列qTを計算する.
4.最適状態系列の復元(例題)
最後に,t=6,5,4,3,2,1として最適状態系列をバックトラックによって復元する.
よって,最適状態系列qT(t=1,2,3,4,5,6)は以下の通りとなる.
この結果は,今回の隠れマルコフモデルで推定した結果,品詞系列名詞-動詞-形容詞-名詞-前置詞-名詞(訳:ジョンは夕食にフライドチキンを食べる)の方が尤もらしいと推定されたことを表している.もちろん,別の隠れマルコフモデルを用いて推定した場合に結果が変わることもある.ここで重要となるのは隠れマルコフモデルのパラメータ(遷移確率,出力確率)であるが,それらの決定には出力系列からモデルのパラメータを推定するバウム・ウェルチアルゴリズムが用いられる(説明は割愛).
以上で,Viterbiアルゴリズムによる推定の手順の解説は終了である.最後に,Viterbiアルゴリズムの応用可能性について確認しよう.
Viterbiアルゴリズムの応用可能性
Viterbiアルゴリズムはどのような分野で応用できるのであろうか.応用分野のひとつに自然言語処理分野が挙げられる.本解説の導入でも述べた通り,Viterbiアルゴリズムは形態素解析器であるMeCab,Chasen,JUMANで解探索アルゴリズムとして採用されている.複数の解釈があり得る自然言語を形態素ごとに分解し品詞情報を付加する場合,複数の分解パターンを確率的に比較することができる.
その他にも,音声処理分野や文字認識分野でもViterbiアルゴリズムによる推定は大いに貢献している.
参考
【論文】
・Error Bounds for Convolutional Codes and an Asymptotically Optimum Decoding Algorithm
・The Viterbi Algorithm
【書籍】
・北 研二:言語と計算ー4 確率的言語モデル(1999).
【Webサイト】
・ビタビアルゴリズム – wikipedia
・動的計画法 – wikipedia
・分割統治法 – wikipedia
・メモ化 – wikipedia
・ビタビアルゴリズム【入門】具体例で分かりやすく解説!(Viterbi)
・隠れマルコフモデル(HMM)について
・HMM viterbi
・2009 Open Campus No.3 言コミ報告<体験授業x3>!(8/2)